 DFS and BFS
DFS and BFS
作者:画手大鹏
链接:https://leetcode-cn.com/leetbook/read/illustrate-lcof/eoy8q2/
来源:力扣(LeetCode)
2
3
# DFS
# 剑指 Offer 12. 矩阵中的路径
题目描述 请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左、右、上、下移动一格。如果一条路径经过了矩阵的某一格,那么该路径不能再次进入该格子。例如,在下面的3×4的矩阵中包含一条字符串 “bfce” 的路径(路径中的字母用加粗标出)。
[["a","b","c","e"], ["s","f","c","s"], ["a","d","e","e"]]
但矩阵中不包含字符串 “abfb” 的路径,因为字符串的第一个字符 b 占据了矩阵中的第一行第二个格子之后,路径不能再次进入这个格子。
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
2
示例 2:
输入:board = [["a","b"],["c","d"]], word = "abcd"
输出:false
2
**思路**
- 标签:深度优先搜索
- 整体思路:
- 题目可以模拟为 DFS 的过程,即从一个方向搜索到底,再回溯上一个节点,沿另一个方向继续搜索,递归进行。在搜索过程中,若遇到该路径不可能与目标字符串匹配的情况,执行剪枝,立即返回。
- 复杂度:
- 时间复杂度:O(3^k I J)。 一次搜索完全部矩阵的时间复杂度为 O(I J) ,共需要 3^k 次搜索
- 空间复杂度:搜索过程中的递归深度不超过 K ,因此系统因函数调用累计使用的栈空间占用 O(K)
算法流程
- 递推参数: 当前元素在矩阵 board 中的行列索引 i 和 j ,当前目标字符在 word 中的索引 k 。
- 终止条件:
- 行或列索引越界 或 当前矩阵元素与目标字符不同 或 当前矩阵元素已访问过,返回 false
- 目标字符串全部匹配成功,返回 true
- 将当前元素值暂存在 tmp 中,修改为字符 ‘/’,以此标记为该元素已访问。通过 tmp 变量存值可以免去新建一个访问过的字符串数组,节省空间。
- 向其他方向继续搜索, 并记录结果, 遇 false 即返回
- 将 tmp 值还原到当前元素
- 返回结果
class Solution {
public boolean exist(char[][] board, String word) {
char[] words = word.toCharArray();
for(int i = 0; i < board.length; i++) {
for(int j = 0; j < board[0].length; j++) {
if(dfs(board, words, i, j, 0)) return true;
}
}
return false;
}
boolean dfs(char[][] board, char[] word, int i, int j, int k) {
// 行或列索引越界 或 当前矩阵元素与目标字符不同 或 当前矩阵元素已访问过,返回 false
if(i >= board.length || i < 0 || j >= board[0].length || j < 0 || board[i][j] != word[k]) return false;
// 目标字符串全部匹配成功,返回 true
if(k == word.length - 1) return true;
char tmp = board[i][j];
// 将当前元素值暂存在 tmp 中,修改为字符 ‘/’,以此标记为该元素已访问。通过 tmp 变量存值可以免去新建一个访问过的字符串数组,节省空间
board[i][j] = '/';
// 向其他方向继续搜索, 并记录结果, 遇 false 即返回
boolean result = dfs(board, word, i + 1, j, k + 1) || dfs(board, word, i - 1, j, k + 1) ||
dfs(board, word, i, j + 1, k + 1) || dfs(board, word, i , j - 1, k + 1);
// 将 tmp 值还原到当前元素
board[i][j] = tmp;
// 返回结果
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 剑指 Offer 13. 机器人的运动范围
题目描述
- 地上有一个 m 行 n 列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于 k 的格子。例如,当 k 为 18 时,机器人能够进入方格 [35, 37] ,因为 3+5+3+7=18。但它不能进入方格 [35, 38],因为 3+5+3+8=19。请问该机器人能够到达多少个格子?
示例 1:
输入:m = 2, n = 3, k = 1
输出:3
2
示例 2:
输入:m = 3, n = 1, k = 0
输出:1
2
提示:
- 1 <= n,m <= 100
- 0 <= k <= 20
**思路**
- 标签:dfs
- 整体思路:
- 从原点出发,沿四个方向(本题中两个方向就行了,因为可行区域在原点的右下方)不断拓展,将可到达并且满足坐标数位和不大于 k 的点加入到队列中,直到所有可到达的点都被访问到。
- 复杂度:
- 时间复杂度:O(mn)。
- 空间复杂度:O(mn)。
算法流程
- 递归参数:当前元素在矩阵中的行列索引 i 和 j,是否被访问的标记,矩阵的行列长度
- 终止条件:
- 行列索引越界
- 数位和大于 k
- 已被访问过
- 递推:
- 标记当前元素已被访问
- 计算当前元素的 下、右 两个方向元素的数位和,并开启下层递归
class Solution {
public int movingCount(int m, int n, int k) {
boolean[][] visited = new boolean[m][n];
return dfs(0, 0, m, n, k, visited);
}
private int dfs(int i, int j, int m, int n, int k, boolean visited[][]) {
if (i < 0 || i >= m || j < 0 || j >= n || (i/10 + i%10 + j/10 + j%10) > k || visited[i][j]) {
return 0;
}
// 标记当前元素已被访问
visited[i][j] = true;
// 计算当前元素的 下、右 两个方向元素的数位和,并开启下层递归
return dfs(i + 1, j, m, n, k, visited) +
dfs(i, j + 1, m, n, k, visited) + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 剑指 Offer 27. 二叉树的镜像
题目描述 请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ \
2 7
/ \ / \
1 3 6 9
镜像输出:
4
/ \
7 2
/ \ / \
9 6 3 1
示例 1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
2
限制:
- 0 <= 节点个数 <= 1000
**思路**
- 标签:dfs
- 递归结束条件:
- 当节点 root 为 null 时,说明已经到叶子节点了,递归结束
- 递归过程:
- 初始化当前节点,并且赋值
- 递归原来树的右子树 mirrorTree(root.right),并将该结果挂到当前节点的左子树上
- 递归原来树的左子树 mirrorTree(root.left),并将该结果挂到当前节点的右子树上
- 时间复杂度:O(n),空间复杂度:O(n)
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mirrorTree(TreeNode root) {
TreeNode res = null;
// 当节点 root 为 null 时,说明已经到叶子节点了,递归结束
if(root != null) {
res = new TreeNode(root.val); // 初始化当前节点,并且赋值
res.left = mirrorTree(root.right); // 递归原来树的右子树 mirrorTree(root.right),并将该结果挂到当前节点的左子树上
res.right = mirrorTree(root.left); // 递归原来树的左子树 mirrorTree(root.left), 并将该结果挂到当前节点的右子树上
}
return res;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 剑指 Offer 28. 对称的二叉树
题目描述 给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
示例 1:
输入:root = [1,2,2,3,4,4,3]
输出:true
2
示例 2:
输入:root = [1,2,2,null,3,null,3]
输出:false
2
限制:
- 0 <= 节点个数 <= 1000
**思路**
- 标签:dfs
- 递归结束条件:
- 都为空指针则返回 true
- 只有一个为空则返回 false
- 递归过程:
- 判断两个指针当前节点值是否相等
- 判断 A 的右子树与 B 的左子树是否对称
- 判断 A 的左子树与 B 的右子树是否对称
- 短路:在递归判断过程中存在短路现象,也就是做与操作时,如果前面的值返回 false 则后面的不再进行计算
- 时间复杂度:O(n)
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
return isMirror(root, root);
}
public boolean isMirror(TreeNode t1, TreeNode t2) {
if (t1 == null && t2 == null) return true; // 都为空指针则返回 true
if (t1 == null || t2 == null) return false; // 只有一个为空则返回 false
return (t1.val == t2.val) // 判断两个指针当前节点值是否相等
&& isMirror(t1.right, t2.left) // 判断 A 的右子树与 B 的左子树是否对称
&& isMirror(t1.left, t2.right); // 判断 A 的左子树与 B 的右子树是否对称
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 剑指 Offer 54. 二叉搜索树的第 k 大节点
题目描述
- 给定一棵二叉搜索树,请找出其中第 k 大的节点。
示例 1:
输入: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2
输出: 4
2
3
4
5
6
7
示例 2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
输出: 4
2
3
4
5
6
7
8
9
限制:
- 1 ≤ k ≤ 二叉搜索树元素个数
**思路**
- 标签:树的深度遍历
- 整体思路:二叉搜索树按照中序遍历(左、中、右)可以获得升序数字,题目要找到第 k 大的节点,所以需要数字降序排列,则将中序遍历按照右、中、左遍历即可,遍历的同时找到第 k 个遍历到的值
- 时间复杂度:O(n),空间复杂度:O(1)
算法流程
- 初始化全局变量 curK = k,用于之后计数
- 进行树的右、中、左深度遍历
- 终止条件:root 节点为 null
- 右子树进行递归遍历
- curK 自减一,用于计数,当 curK 为 0 时表示找到第 k 大的节点,则可以结束
- 左子树进行递归遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int res, curK;
public int kthLargest(TreeNode root, int k) {
curK = k;
dfs(root);
return res;
}
public void dfs(TreeNode root) {
// 终止条件:root 节点为 null || curK 为 0 (已找到第 k 大的节点)
if(root == null || curK == 0) return;
// 右子树进行递归遍历
dfs(root.right);
// // curK 自减一,用于计数,当 curK 为 0 时表示找到第 k 大的节点
if(--curK == 0) res = root.val;
// 左子树进行递归遍历
dfs(root.left);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 剑指 Offer 55 - I. 二叉树的深度
题目描述
- 输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
提示:
节点总数 <= 10000
注意:本题与 主站 104 题相同
**思路**
- 标签:树的深度遍历
- 整体思路:二叉树的最大高度,是由其左子树最大高度和右子树的最大高度中取最大值 + 根节点高度 1 计算出来的
- 时间复杂度:O(n),空间复杂度:O(1)
算法流程
- 终止条件:root 节点为 null 时,返回高度为 0
- 求出左子树最大高度、右子树最大高度
- 计算左子树和右子树高度的最大值
- 将上一步的最大值 + 根节点高度 1
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null) return 0;
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 剑指 Offer 68 - II. 二叉树的最近公共祖先
题目描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
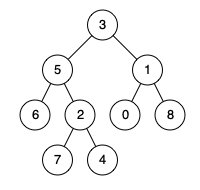
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
2
3
示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
2
3
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
**思路**
- 标签:二叉树、DFS
- 整体思路:
- 祖先节点定义:当前节点的父节点,其父节点的父节点,只要当前节点在某一个节点的子树下,则可以称其为当前节点的祖先节点
- 公共祖先定义:p、q 节点都在某一个节点的子树下或者其自身,则可以称其为 p、q 节点的公共祖先节点
- 最近公共祖先定义:从祖先节点的定义可以知道,如果 x 节点是 p、q 节点的公共祖先,那么 x 节点的祖先节点也一定是 p、q 节点的公共祖先,则距离 p、q 个节点深度最小的为最近公共祖先,通常表现为 p、q 节点不在最近公共祖先的同一个子树上
- 根据题意可知,所有的节点值唯一,则可以根据 p、q 节点不在最近公共祖先的同一个子树上的特征,进行深度优先遍历,找到结果
- 时间复杂度:O(n),空间复杂度:O(n)
算法流程
- 终止条件:
- 当 root 节点为 null 时,说明到达叶子节点的下一层,直接返回 null 即可
- 当 root 节点为 p 或 q 时,说明找到了对应的节点,返回 root 即可
- 递归内容:
- 递归左子树 root.left,得到左子树返回值 left
- 递归右子树 root.right,得到右子树返回值 right
- 返回值:
- 当 left 和 right 都为 null 时,说明当前层 root 的左右子树不包含 p、q 节点,返回 null 即可
- 当 left 为 null 且 right 不为 null 时,说明当前层 root 的左子树不包含 p、q 节点,右子树包含 p、q 节点,则返回右子树 right
- 当 left 不为 null 且 right 为 null 时,说明当前层 root 的左子树包含 p、q 节点,右子树不包含 p、q 节点,则返回左子树 left
- 当 left 和 right 都不为 null 时,说明当前层 root 的左右子树均包含 p、q 节点,返回 root 即可
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q) {
return root;
}
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if(left == null && right == null) {
return null;
} else if(left == null && right != null) {
return right;
} else if(left != null && right == null) {
return left;
} else {
return root;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# BFS
# 剑指 Offer 32 - I. 从上到下打印二叉树
题目描述 从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回:
[3,9,20,15,7]
提示:
- 节点总数 <= 1000
**思路**
- 标签:树的广度遍历
- 整体思路:广度遍历的最常见思路,使用队列按层次存储,然后依次取出,达到按层次进行遍历的效果
- 时间复杂度:O(n),空间复杂度:O(n)
算法流程
- 判断 root 是否为 null,如果为 null 则直接返回空数组
- 初始化队列,并将初始的 root 节点加入队列之中
- 当队列不为空时不断广度遍历二叉树,遍历时依次从队列中取出节点,取出后如果该节点存在左节点则将左节点放入队列中,如果该节点存在右节点则将右节点放入队列中
- 在遍历过程中存储结果,最后将结果按照要求的格式返回
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int[] levelOrder(TreeNode root) {
if(root == null)
return new int[0];
// 初始化队列,并将初始的 root 节点加入队列之中
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
ArrayList<Integer> ans = new ArrayList<>();
// 当队列不为空时不断广度遍历二叉树
while(!queue.isEmpty()) {
TreeNode node = queue.poll(); // 遍历时依次从队列中取出节点
ans.add(node.val);
if(node.left != null) // 如果该节点存在左节点则将左节点放入队列中
queue.add(node.left);
if(node.right != null) // 如果该节点存在右节点则将右节点放入队列中
queue.add(node.right);
}
int[] res = new int[ans.size()];
for(int i = 0; i < ans.size(); i++) {
res[i] = ans.get(i);
}
return res;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 剑指 Offer 32 - II. 从上到下打印二叉树 II
题目描述
- 从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
例如: 给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
2
3
4
5
提示:
- 节点总数 <= 1000
思路
- 标签:树的广度遍历
- 通过广度遍历 BFS 可以进行每一层的节点值获取,通过队列的方式,将当前层节点的下一层子节点放入队列中,用于下一次循环取值,同时将本层的节点放入到本层数组中,当前层循环结束后塞入结果数组中
- 时间复杂度:O(n),空间复杂度:O(n)
算法流程
- 初始化队列 queue 和结果集 res
- 当 root == null 时,直接返回空的结果集 res
- 将 root 添加到 queue 中,用于下面的第一次循环
- 当 queue 不为空时始终进行循环遍历,新建当前层结果集 level,并将 queue 中当前层的节点一一取出,将节点值添加到 level 中,如果节点存在左子树,则将左子树节点放入 queue 中,如果节点存在右子树,则将右子树节点放入 queue 中
- 结束循环,返回结果集 res
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
// // 初始化结果集合 res,如果 root == null 则直接返回空的结果集
List<List<Integer>> res = new ArrayList<>();
if(root == null)
return res;
// 将 root 添加到 queue 中,用于下面的第一次循环
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while(!queue.isEmpty()) {
List<Integer> level = new ArrayList<>(); // 新建当前层结果集 level
int len = queue.size();
for(int i = 0; i < len; i++) {
TreeNode treeNode = queue.poll(); // 将 queue 中当前层的节点一一取出
level.add(treeNode.val); // 将节点值添加到 level 中
if(treeNode.left != null) // 如果节点存在左子树,则将左子树节点放入 queue 中
queue.add(treeNode.left);
if(treeNode.right != null) // 如果节点存在右子树,则将右子树节点放入 queue 中
queue.add(treeNode.right);
}
res.add(level);
}
return res;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 剑指 Offer 32 - III. 从上到下打印二叉树 III
题目描述
- 请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
例如: 给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[20,9],
[15,7]
]
2
3
4
5
提示:
- 节点总数 <= 1000
**思路**
- 标签:双端队列、树的广度遍历
- 整体思路:从 root 节点开始,每次取下一层的所有节点放入队列中,放入队列时如果层数为奇数,则依次放到当前层结果的尾部,达到从左到右的顺序打印效果。如果层数为偶数,则依次放到当前层结果的头部,达到从右向左的顺序打印效果。
- 时间复杂度:O(n),空间复杂度:O(n)
算法流程
- 初始化结果集合 res,如果 root == null 则直接返回空的结果集
- 初始化队列 queue,并将 root 添加到队列中
- 当队列不为空时,将当前 queue 中的所有值取出,构造每一层的结果 list
- 如果层数为奇数层,则进行尾插法,将结果按顺序在 list 尾部进行插入
- 如果层数为偶数层,则进行头插法,将结果按顺序在 list 头部进行插入
- 将当前层结果 list 加入到 res 中,最后返回 res
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
// 初始化结果集合 res,如果 root == null 则直接返回空的结果集
List<List<Integer>> res = new ArrayList<>();
if(root == null)
return res;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while(!queue.isEmpty()) {
LinkedList<Integer> list = new LinkedList<>();
int len = queue.size();
for(int i = 0;i < len;i++) {
// 当队列不为空时,将当前 queue 中的所有值取出,构造每一层的结果 list
TreeNode treeNode = queue.poll();
if(res.size() % 2 == 0)
list.addLast(treeNode.val);
else
list.addFirst(treeNode.val);
if(treeNode.left != null)
queue.add(treeNode.left);
if(treeNode.right != null)
queue.add(treeNode.right);
}
res.add(list);
}
return res;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
题目描述
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
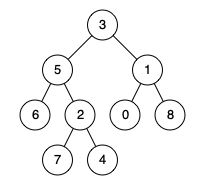
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
2
3
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
2
3
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
**思路**
- 标签:二叉搜索树
- 整体思路:
- 祖先节点定义:当前节点的父节点,其父节点的父节点,只要当前节点在某一个节点的子树下,则可以称其为当前节点的祖先节点
- 公共祖先定义:p、q 节点都在某一个节点的子树下或者其自身,则可以称其为 p、q 节点的公共祖先节点
- 最近公共祖先定义:从祖先节点的定义可以知道,如果 x 节点是 p、q 节点的公共祖先,那么 x 节点的祖先节点也一定是 p、q 节点的公共祖先,则距离 p、q 个节点深度最小的为最近公共祖先,通常表现为 p、q 节点不在最近公共祖先的同一个子树上
- 根据题意可知,树是二叉搜索树,所有的节点值唯一,则可以根据 p、q 节点不在最近公共祖先的同一个子树上的特征,进行循环遍历,找到结果
- 时间复杂度:O(n),空间复杂度:O(1)
算法流程
- 首先在同一个二叉树上的 p、q 节点一定存在最近公共祖先,所以定义一个循环直到找到该节点为止
- 如果 root.val > p.val && root.val > q.val,说明 p、q 节点都在 root 节点的左子树上,令 root = root.left,继续查询
- 如果 root.val < p.val && root.val < q.val,说明 p、q 节点都在 root 节点的右子树上,令 root = root.right,继续查询
- 如果 root.val == p.val,说明 p 节点就是最近公共祖先
- 如果 root.val == q.val,说明 q 节点就是最近公共祖先
- 如果 root.val > p.val && root.val < q.val 或者 root.val < p.val && root.val > q.val,说明 root 节点就是最近公共祖先
- 4、5、6 三部分可以合并为其他情况,直接返回 root 即可
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// 首先在同一个二叉树上的 p、q 节点一定存在最近公共祖先,所以定义一个循环直到找到该节点为止
while (true) {
if (root.val > p.val && root.val > q.val) {
// 说明 p、q 节点都在 root 节点的左子树上
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
// 说明 p、q 节点都在 root 节点的右子树上
root = root.right;
} else {
return root;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 递归
# 剑指 Offer 07. 重建二叉树
题目描述
- 输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
示例 1:
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
**思路**
- 标签:递归
- 整体思路:
- 根据二叉树的遍历特点可知:
- 前序遍历首个元素为根节点;
- 在中序遍历中可由根节点位置将其分为‘左子树’‘根节点’‘右子树’;
- 在中序遍历中可知左右子树的节点数量。
- 因此可以确定三个节点关系,根据树的特点,我们很自然的可以使用递归方法。
- 根据二叉树的遍历特点可知:
- 复杂度:
- 时间复杂度:O(n)。 n 为树的节点数量。初始化 HashMap 需遍历 inOrder ,占用 O(n);递归占用 O(n) 。(最差情况为所有子树只有左节点,树转化为链表,此时递归深度 O(n) ;平均情况下递归深度 O(log n)
- 空间复杂度:O(n)。HashMap 使用 O(n) 额外空间;递归操作需使用 O(n) 额外空间。
算法流程
- 递推参数: 前序遍历中根节点的索引 preRoot、中序遍历左边界 inLeft、中序遍历右边界 inRight。
- 终止条件: 当 inLeft > inRight ,子树中序遍历为空,说明已经越过叶子节点,此时返回 null 。当 inLeft = inRight 时, 代表只有该节点本身。
- 接着
- 由先序遍历中确定根节点 root
- 左子树的根节点就是 左子树的(前序遍历)第一个,就是+1,左边边界就是 inLeft,右边边界是中间区分的根节点在中序中的索引 -1
- 右子树的根,是右子树(前序遍历)的第一个,也就是当前根节点 加上左子树的数量
- 返回 root
class Solution {
HashMap<Integer, Integer> midMap = new HashMap<>();
int[] preOrder;
public TreeNode buildTree(int[] preOrder, int[] inOrder) {
// 由先序遍历中确定根节点 root
this.preOrder = preOrder;
//为了提升搜索效率,使用哈希表存储中序遍历的值与索引的映射关系。
for(int i = 0; i < preOrder.length; i++) {
midMap.put(inOrder[i], i);
}
return build(0, 0, inOrder.length - 1);
}
public TreeNode build(int preRoot, int inLeft, int inRight) {
//终止条件
// 当 inLeft > inRight ,子树中序遍历为空,说明已经越过叶子节点,
// 此时返回 null 。当 inLeft = inRight 时, 代表只有该节点本身。
if(inLeft > inRight) {
return null;
}
//构建根节点
TreeNode root = new TreeNode(this.preOrder[preRoot]);
//在中序map中获取根节点的索引
int inRootIndex = midMap.get(this.preOrder[preRoot]);
// 左子树的根节点,左边边界,右边边界
root.left = build(preRoot + 1, inLeft, inRootIndex - 1);
// 右子树的根节点 = 当前根节点 加上左子树的数量
// 右子树的根节点,左边边界,右边边界
root.right = build(preRoot + (inRootIndex - 1 - inLeft + 1) + 1, inRootIndex + 1, inRight);
return root;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 剑指 Offer 26. 树的子结构
题目描述
- 输入两棵二叉树 A 和 B,判断 B 是不是 A 的子结构。(约定空树不是任意一个树的子结构)
- B 是 A 的子结构, 即 A 中有出现和 B 相同的结构和节点值。
例如: 给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
2
3
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例 1:
输入:A = [1,2,3], B = [3,1]
输出:false
2
示例 2:
输入:A = [3,4,5,1,2], B = [4,1]
输出:true
2
限制:
- 0 <= 节点个数 <= 10000
**思路**
- 标签:递归
- 整体思路:
- 子树:若 B 是 A 的子树,则 A 包含 B 的所有结点,并且 B 的叶子节点一定是A的叶子节点。 也就是 A 只要包含了 B 的一个结点,就得包含这个结点下的所有节点。
- 子结构:若 B 是 A 的子结构,则 A 包含 B 的所有结点,但 B 的叶子节点不一定是 A 的叶子节点。也就是子结构 B 是 A 树的任意一部分。
- 此题目是 子结构相关。此题目约定空树,不为任何一棵树的子结构。如果 B 为 A 的子结构,则B的根节点一定是A的任意一个节点。
- 双重递归。
- 复杂度:
- 时间复杂度 O(mn),m 和 n 为树 A 和 B 的节点数量。
- 空间复杂度 O(m),m 是树 A 的递归深度。
算法流程
- 双重递归第一重,isSubStructure
- 判断 pRoot2 是否为 pRoot1 的子结构 (约定空树,不为任何一棵树的子结构)
- 约定空树不是任意一个树的子结构. 所以 A 不可为空树,且 B 不可为空树。
- B 是以 "A 为根节点" 的子结构,或者 B 是 "A 的左子树" 的子结构,或者B是 "A 的右子树" 的子结构。注意三者为 或 的关系
- 相当于对 A 进行了前序遍历: 根->左->右
- 双重递归第二重,isInclude
- 判断 pRoot1 是否包含 pRoot2 (从集合关系分析,空集属于任何集合的子集)
- pRoot2 为空,则 pRoot1 包含 pRoot2
- pRoot1 为空,则 pRoot1 不包含 pRoot2
- pRoot1,pRoot2 都不为空, 但节点值不同,则 pRoot1 不包含 pRoot2,即不具备包含关系
- 如果值相同,则判断他们的左右节点是否也是包含关系(必须都是包含关系才行)
- 递归判断 A 的左节点和 B 的左节点是否相等, 递归判断 A 的右节点和 B 的右节点是否相等
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
if (A == null || B == null)
return false;
// B 是以 "A 为根节点" 的子结构,或者 B 是 "A 的左子树" 的子结构,或者B是 "A 的右子树" 的子结构。注意三者为 或 的关系
// 相当于对 A 进行了前序遍历: 根->左->右
return isSub(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B);
}
public boolean isSub(TreeNode A, TreeNode B) {
if (B == null)
return true;
if (A == null || A.val != B.val)
return false;
return isSub(A.left, B.left) && isSub(A.right, B.right);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 剑指 Offer 64. 求1+2+…+n
题目描述
- 求 1+2+...+n ,要求不能使用乘除法、for、while、if、else、switch、case 等关键字及条件判断语句(A?B:C)。
示例 1:
输入: n = 3
输出: 6
2
示例 2:
输入: n = 9
输出: 45
2
限制:
- 1 <= n <= 10000
**思路**
- 标签:递归、短路
- 整体思路:
- 首先由于题目限制,排除了公式计算、循环迭代和普通递归的方式
- 普通递归算法中的终止条件和条件判断可以用与运算的短路效应来替代
- 复杂度:
- 时间复杂度:O(n)。需要递归计算 n 次
- 空间复杂度:O(n)。递归产生的函数调用栈深度为 n
- 算法流程
- 普通递归的方式求和代码如下:
class Solution {
public int sumNums(int n) {
return n == 0 ? 0 : n + sumNums(n - 1);
}
};
2
3
4
5
- 与运算的短路效应指的是,当出现 conditionA && conditonB 场景时,如果 conditionA 不成立,那么conditionB也不会执行
- 因为短路效应,所以其中的三元运算符条件判断可以用与运算来进行代替
class Solution {
public int sumNums(int n) {
// 其中 tmp 和 (n += sumNums(n - 1)) > 0 中的大于0条件都是为了做短路运算符合语法要求加的,并没有实际意义
boolean tmp = n > 0 && (n += sumNums(n - 1)) > 0;
return n;
}
}
2
3
4
5
6
7