 Data Structure
Data Structure
作者:Krahets
链接:https://leetcode-cn.com/leetbook/read/illustration-of-algorithm/r81qpe/
来源:力扣(LeetCode)
2
3
# 前言
- 数据结构是为实现对计算机数据有效使用的各种数据组织形式,服务于各类计算机操作。不同的数据结构具有各自对应的适用场景,旨在降低各种算法计算的时间与空间复杂度,达到最佳的任务执行效率。
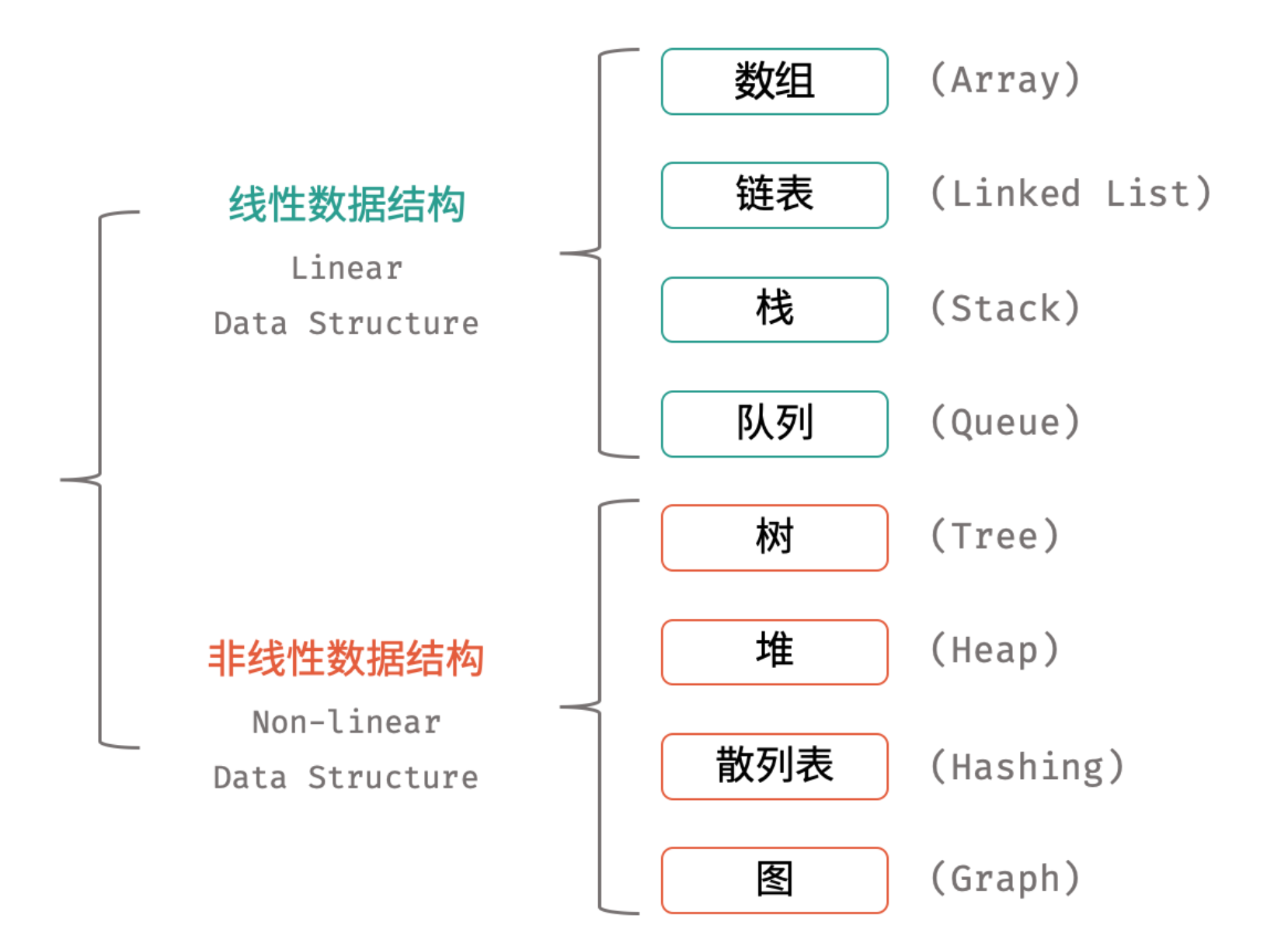
- 如下图所示,常见的数据结构可分为「线性数据结构」与「非线性数据结构」,具体为:「数组」、「链表」、「栈」、「队列」、「树」、「图」、「散列表」、「堆」。
# Big O Notation
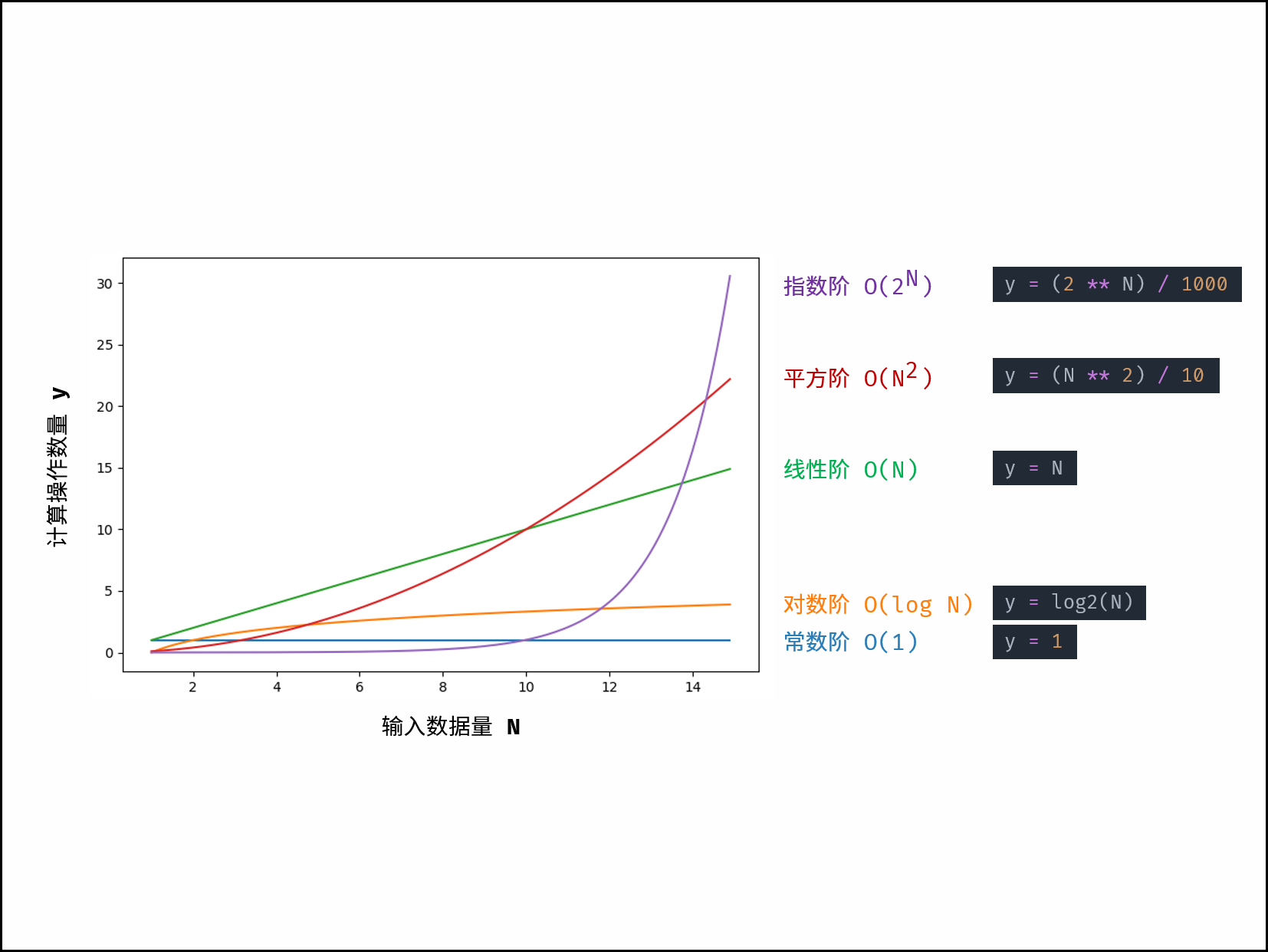
- 根据输入数据的特点,时间复杂度具有「最差」、「平均」、「最佳」三种情况,分别使用 O , Θ , Ω 三种符号表示
- 根据从小到大排列,常见的算法时间复杂度主要有:(Big O notation) To describe the performance of an algorithm (Scale well or not)

- Comparison:
# 算法复杂度
算法复杂度旨在计算在输入数据量 N 的情况下,算法的「时间使用」和「空间使用」情况;体现算法运行使用的时间和空间随「数据大小 N 」而增大的速度。
算法复杂度主要可从 时间 、空间 两个角度评价
「输入数据大小 N 」指算法处理的输入数据量;根据不同算法,具有不同定义,例如:
排序算法: N 代表需要排序的元素数量;
搜索算法: N 代表搜索范围的元素总数,例如数组大小、矩阵大小、二叉树节点数、图节点和边数等;
# 时间复杂度
- 时间: 假设各操作的运行时间为固定常数,统计算法运行的「计算操作的数量」 ,以代表算法运行所需时间;
- 统计的是算法的「计算操作数量」,而不是「运行的绝对时间」。计算操作数量和运行绝对时间呈正相关关系,并不相等。算法运行时间受到「编程语言 、计算机处理器速度、运行环境」等多种因素影响。例如,同样的算法使用 Python 或 C++ 实现、使用 CPU 或 GPU 、使用本地 IDE 或力扣平台提交,运行时间都不同。
- 体现的是计算操作随数据大小 N 变化时的变化情况。假设算法运行总共需要「 1 次操作」、「 100 次操作」,此两情况的时间复杂度都为常数级 O(1) ;需要「 N 次操作」、「 100N 次操作」的时间复杂度都为 O(N) 。
# 常数 
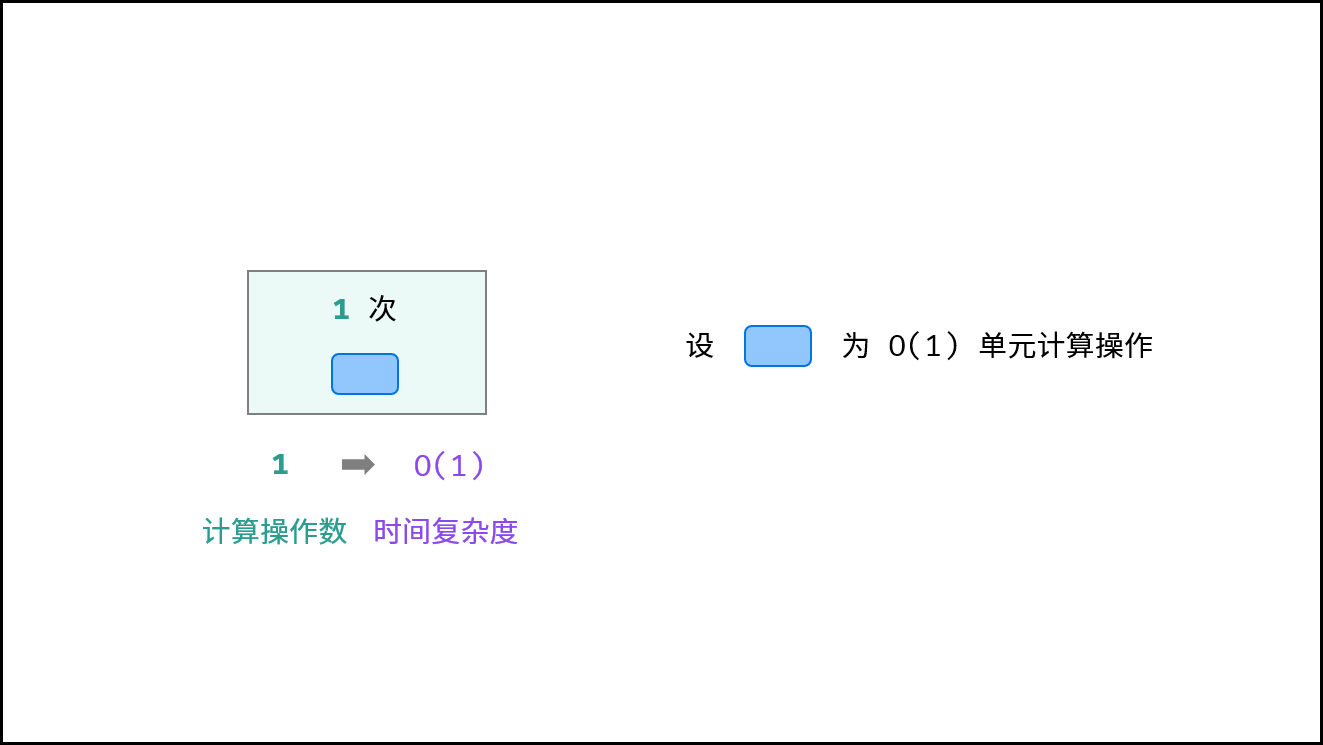
- 运行次数与 N 大小呈常数关系,即不随输入数据大小 N 的变化而变化。
public void log(int[] numbers) {
System.out.println(numbers[0]); // O(1)
}
2
3
- Runs in constant time
- Size of the input does not matter
- Only run one time
- Constant Time
# 对数 
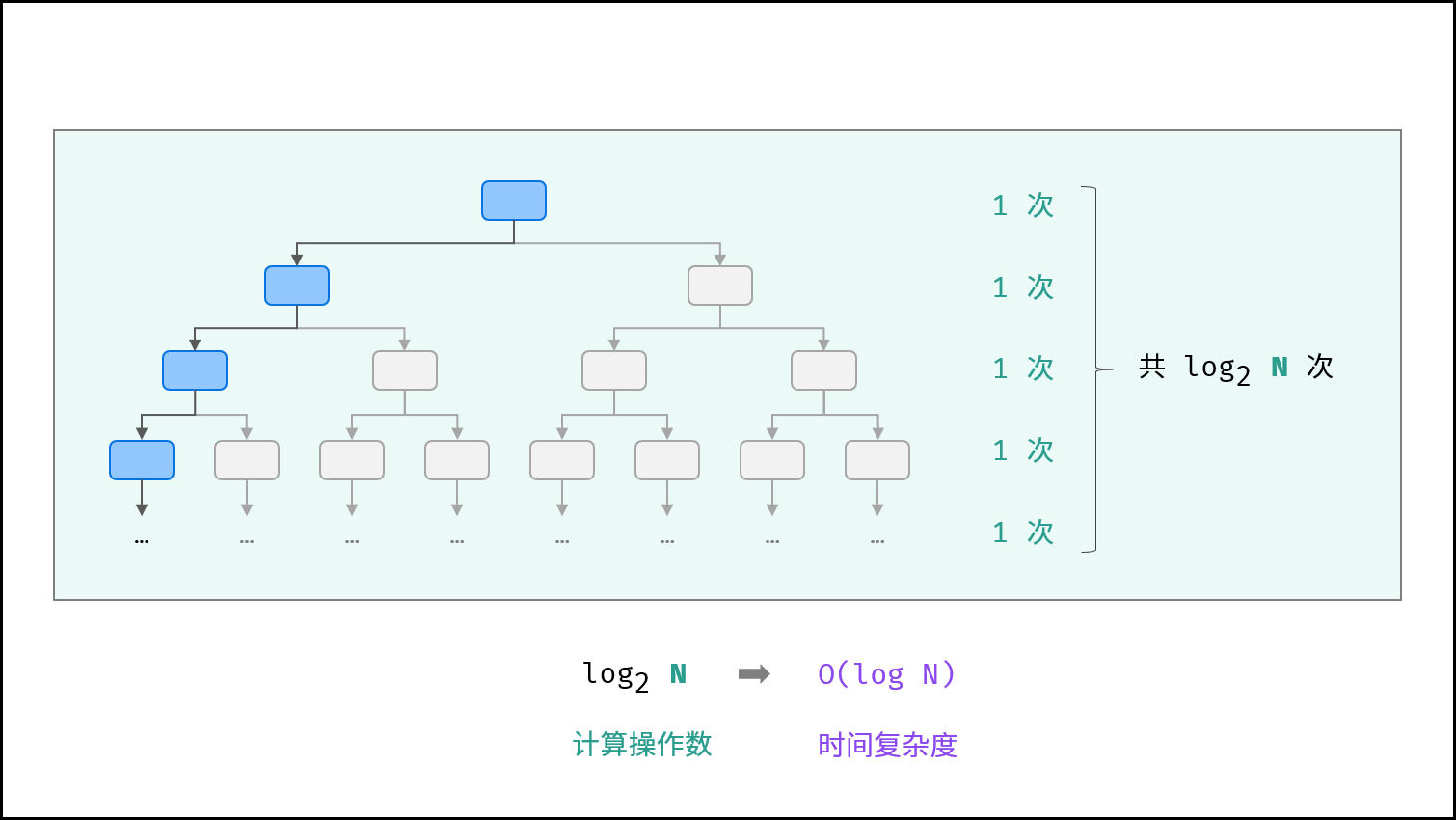
对数阶与指数阶相反,指数阶为 “每轮分裂出两倍的情况” ,而对数阶是 “每轮排除一半的情况” 。对数阶常出现于**「二分法」、「分治」**等算法中,体现着 “一分为二” 或 “一分为多” 的算法思想。
设循环次数为 m ,则输入数据大小 N 与
呈线性关系,两边同时取
对数,则得到循环次数 m 与
呈线性关系,即时间复杂度为
如以下代码所示,对于不同 a 的取值,循环次数 m 与
呈线性关系 ,时间复杂度为
。而无论底数 a 取值,时间复杂度都可记作
,根据对数换底公式的推导如下:
int algorithm(int N) {
int count = 0;
float i = N;
int a = 3;
while (i > 1) {
i = i / a;
count++;
}
return count;
}
2
3
4
5
6
7
8
9
10
- Runs in logarithmic time
- More efficient than linear or quadratic growth

# 线性 
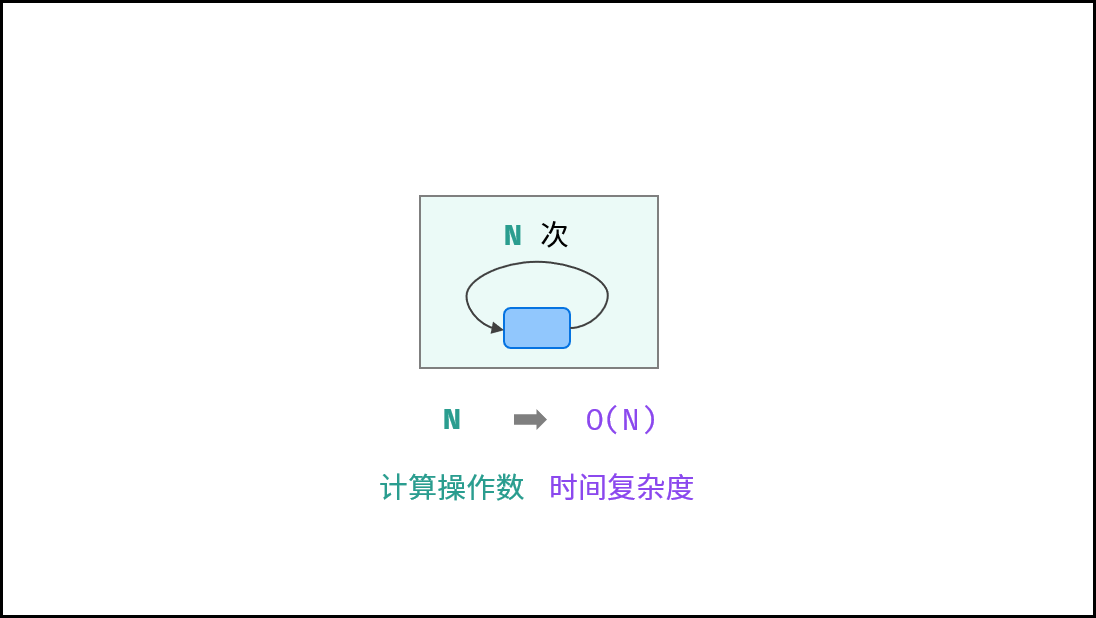
- 循环运行次数与 N 大小呈线性关系,时间复杂度为 O(N) 。
public void log(int[] numbers) {
for (int number : numbers)
System.out.println(number);
}
2
3
4
- Linear growth
- Depends on the size of the input
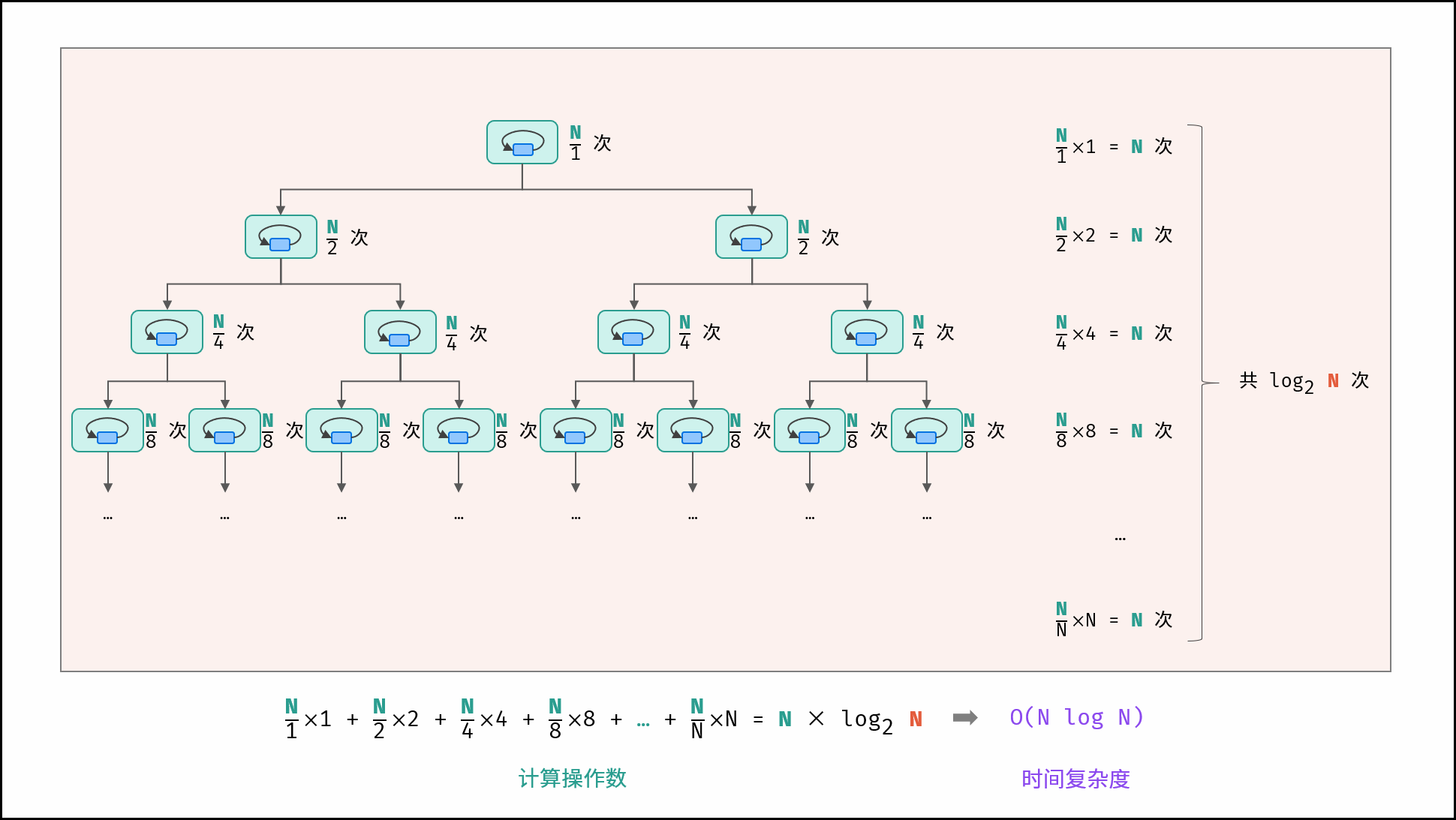
# 线性对数 
- 两层循环相互独立,第一层和第二层时间复杂度分别为
;
int algorithm(int N) {
int count = 0;
float i = N;
while (i > 1) {
i = i / 2;
for (int j = 0; j < N; j++)
count++;
}
return count;
}
2
3
4
5
6
7
8
9
10
- 线性对数阶常出现于排序算法,例如「快速排序」、「归并排序」、「堆排序」等,其时间复杂度原理如下图所示。
# 平方 
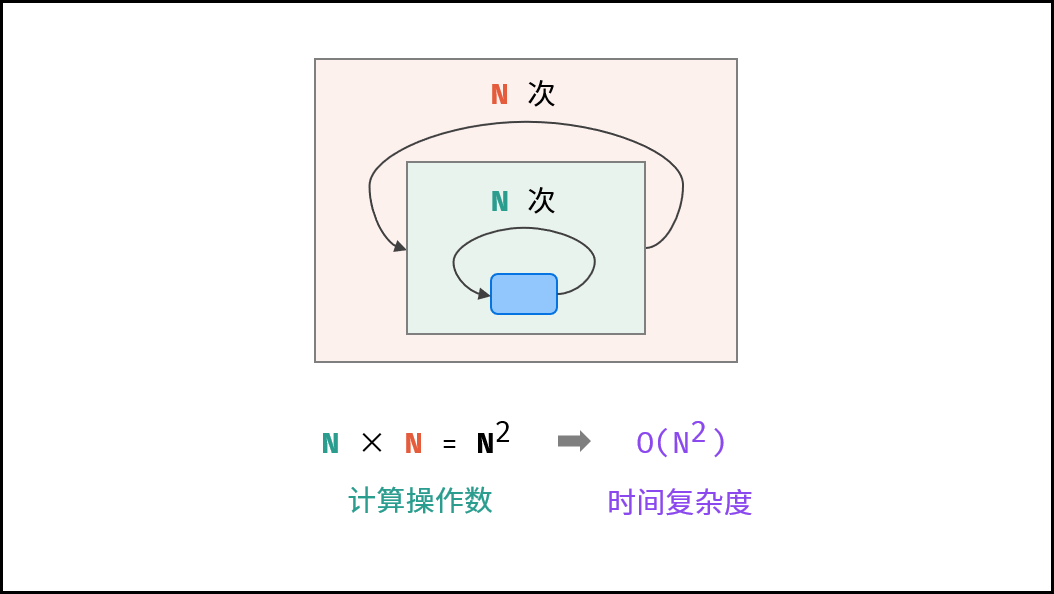
- 两层循环相互独立,都与 N 呈线性关系,因此总体与 N 呈平方关系,时间复杂度为
- Runs in quadratic time
public void log(int[] numbers) {
for (int first : numbers)
for (int second: numbers)
System.out.println(first + "," + second);
}
2
3
4
5
# 指数 O( )
)
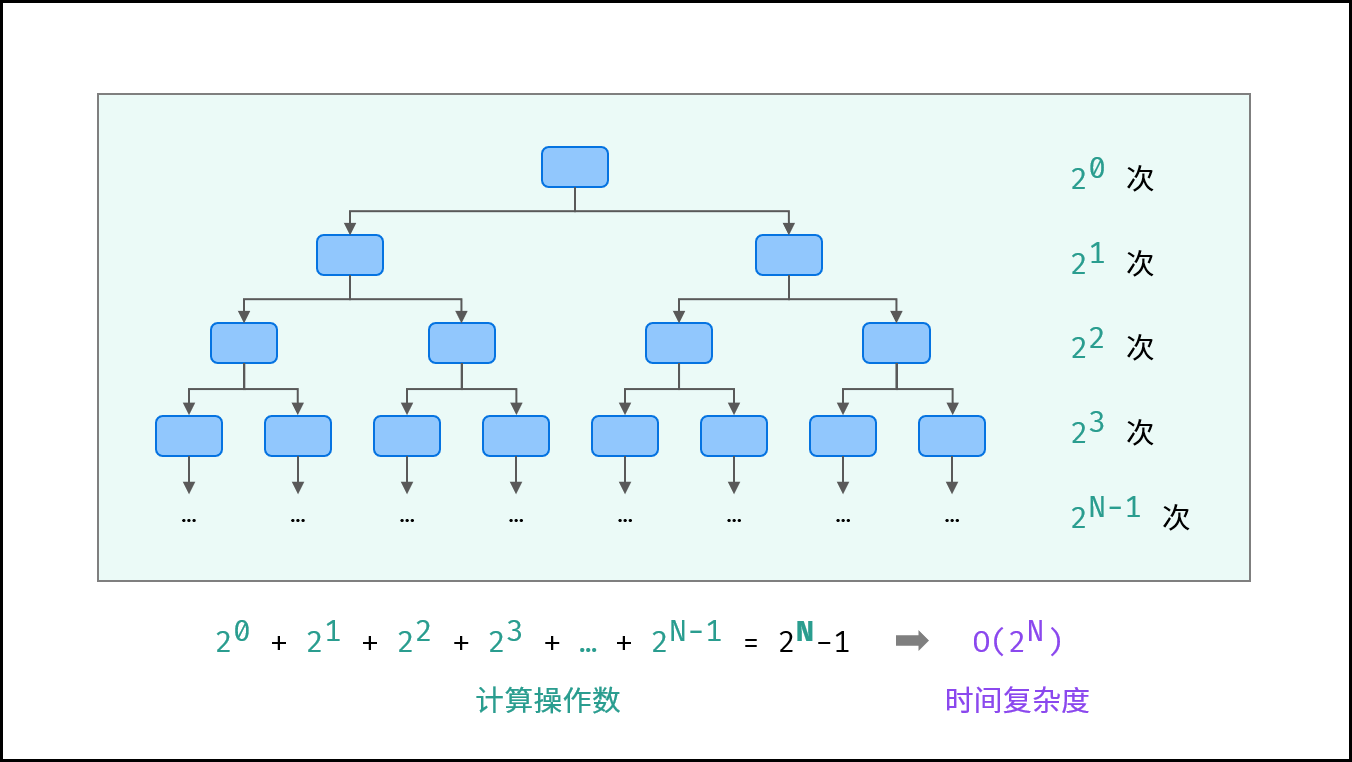
- 生物学科中的 “细胞分裂” 即是指数级增长。初始状态为 11 个细胞,分裂一轮后为 22 个,分裂两轮后为 44 个,……,分裂 NN 轮后有
个细胞。
- 算法中,指数阶常出现于递归:
int algorithm(int N) {
if (N <= 0) return 1;
int count_1 = algorithm(N - 1);
int count_2 = algorithm(N - 1);
return count_1 + count_2;
}
2
3
4
5
6
- The opposite of logarithmic growth
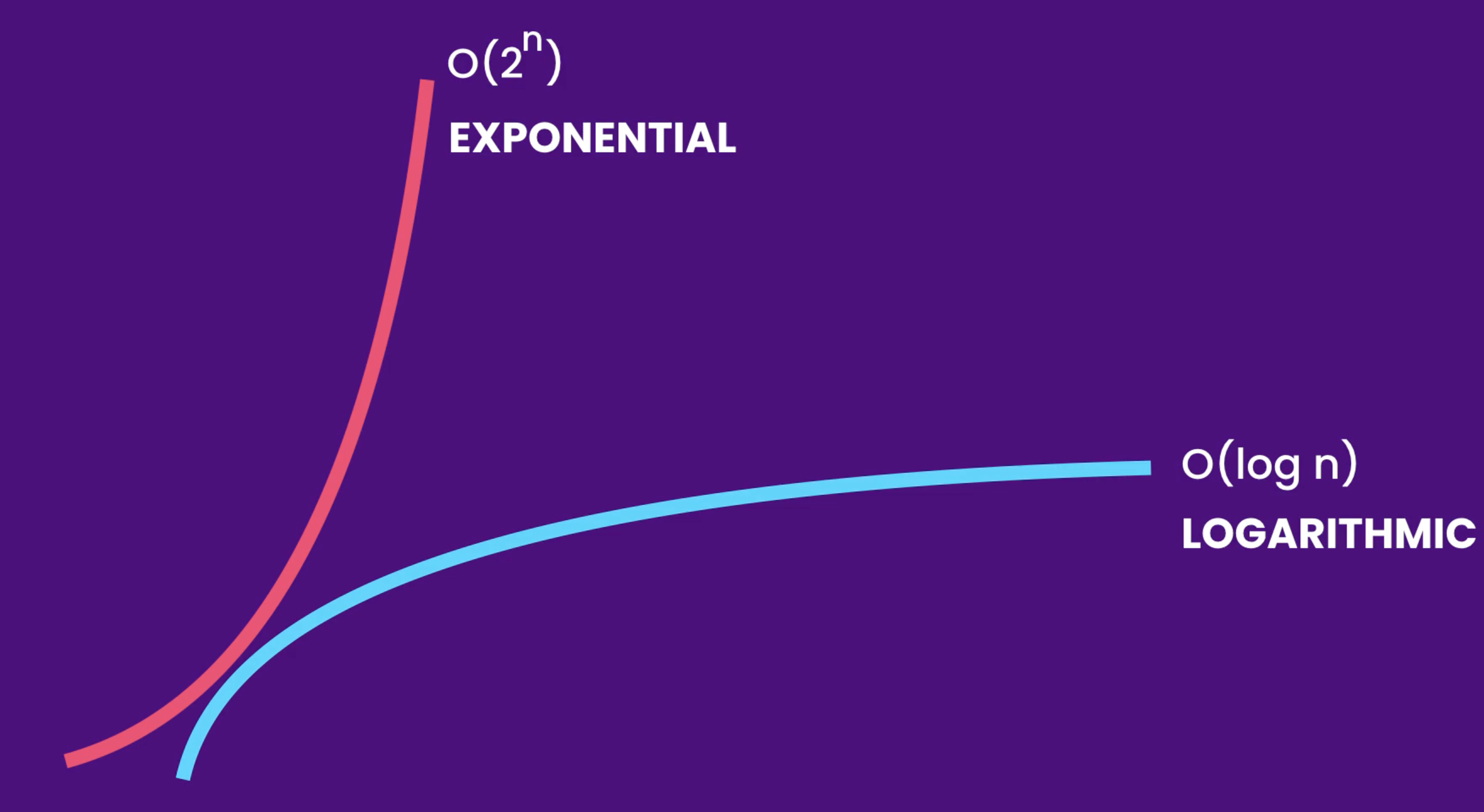
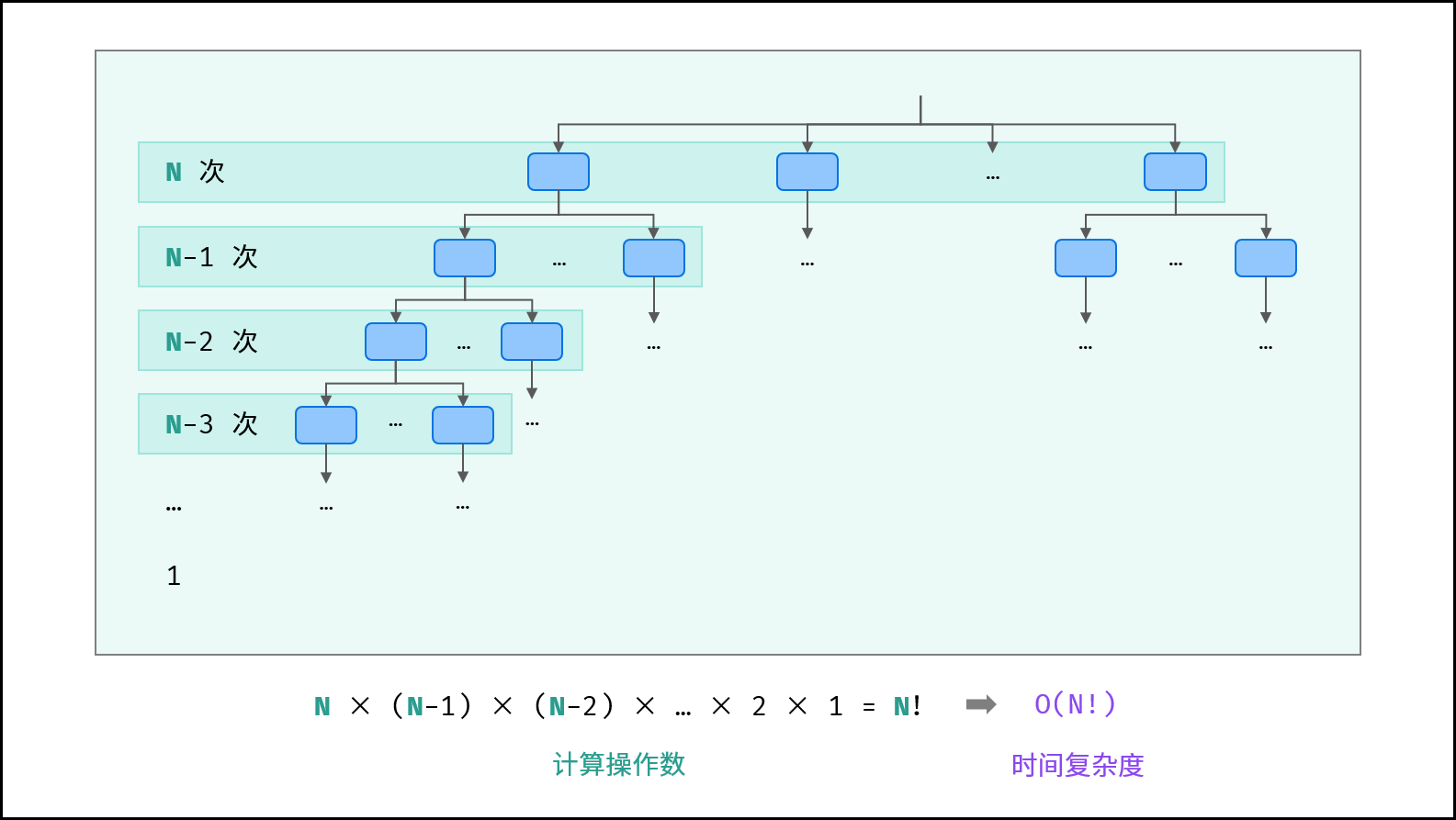
# 阶乘 
阶乘阶对应数学上常见的 “全排列” 。即给定 NN 个互不重复的元素,求其所有可能的排列方案,则方案数量为:
如下图与代码所示,阶乘常使用递归实现,算法原理:第一层分裂出 N 个,第二层分裂出 N - 1N−1 个,…… ,直至到第 N 层时终止并回溯。
int algorithm(int N) {
if (N <= 0) return 1;
int count = 0;
for (int i = 0; i < N; i++) {
count += algorithm(N - 1);
}
return count;
}
2
3
4
5
6
7
8
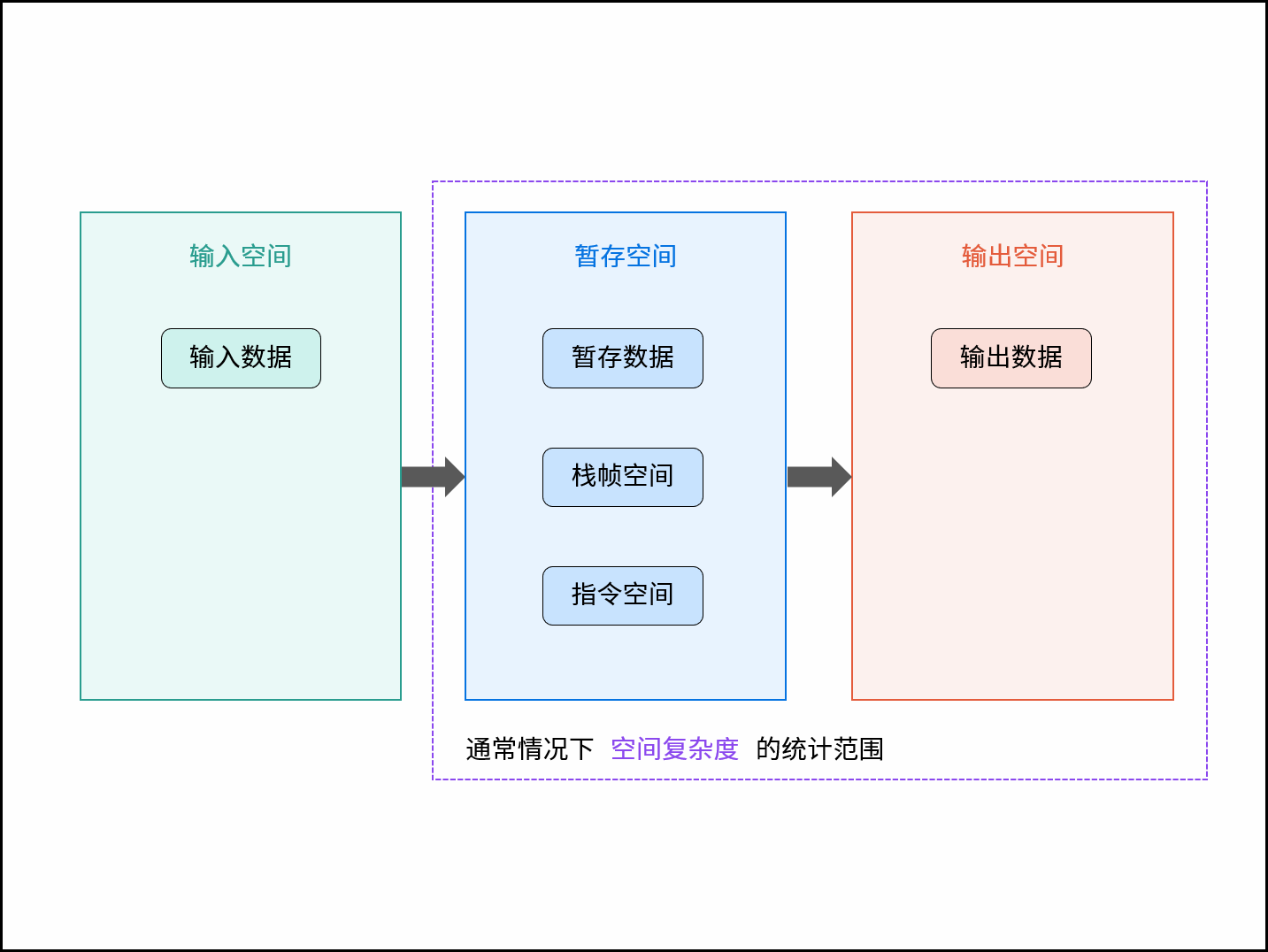
# 空间复杂度
- 空间: 统计在最差情况下,算法运行所需使用的「最大空间」;
- 空间复杂度涉及的空间类型有:
- 输入空间: 存储输入数据所需的空间大小;
- 暂存空间: 算法运行过程中,存储所有中间变量和对象等数据所需的空间大小;
- 输出空间: 算法运行返回时,存储输出数据所需的空间大小;
- 通常情况下,空间复杂度指在输入数据大小为 N 时,算法运行所使用的「暂存空间」+「输出空间」的总体大小。
而根据不同来源,算法使用的内存空间分为三类:
- 指令空间:
- 编译后,程序指令所使用的内存空间。
- 数据空间:
- 算法中的各项变量使用的空间,包括:声明的常量、变量、动态数组、动态对象等使用的内存空间。
class Node {
int val;
Node next;
Node(int x) { val = x; }
}
void algorithm(int N) {
int num = N; // 变量
int[] nums = new int[N]; // 动态数组
Node node = new Node(N); // 动态对象
}
2
3
4
5
6
7
8
9
10
11
- 栈帧空间:
- 程序调用函数是基于栈实现的,函数在调用期间,占用常量大小的栈帧空间,直至返回后释放。如以下代码所示,在循环中调用函数,每轮调用 test() 返回后,栈帧空间已被释放,因此空间复杂度仍为 O(1) 。
int test() {
return 0;
}
void algorithm(int N) {
for (int i = 0; i < N; i++)
test();
}
2
3
4
5
6
7
8
算法中,栈帧空间的累计常出现于递归调用。如以下代码所示,通过递归调用,会同时存在 N 个未返回的函数 algorithm() ,此时累计使用 O(N) 大小的栈帧空间。
int algorithm(int N) {
if (N <= 1) return 1;
return algorithm(N - 1) + 1;
}
2
3
4
符号表示
- 通常情况下,空间复杂度统计算法在 “最差情况” 下使用的空间大小,以体现算法运行所需预留的空间量,使用符号 O 表示。
- 最差情况有两层含义,分别为「最差输入数据」、算法运行中的「最差运行点」。例如以下代码:
输入整数 N ,取值范围
;
void algorithm(int N) {
int num = 5; // O(1)
int[] nums = new int[10]; // O(1)
if (N > 10)
nums = new int[N]; // O(N)
}
2
3
4
5
6
- 最差输入数据: 当
时,数组 nums 的长度恒定为 10 ,空间复杂度为
;当 N>10 时,数组 nums 长度为 N ,空间复杂度为 O(N) ;因此,空间复杂度应为最差输入数据情况下的 O(N)。
- 最差运行点: 在执行 nums = [0] * 10 时,算法仅使用 O(1) 大小的空间;而当执行 nums = [0] * N 时,算法使用 O(N) 的空间;因此,空间复杂度应为最差运行点的 O(N) 。
# 常数
- 普通常量、变量、对象、元素数量与输入数据大小 NN 无关的集合,皆使用常数大小的空间。
# 对数
- 对数阶常出现于分治算法的栈帧空间累计、数据类型转换等,例如:
- 快速排序 ,平均空间复杂度为
,最差空间复杂度为 O(N) 。拓展知识:通过应用 Tail Call Optimization ,可以将快速排序的最差空间复杂度限定至 O(N) 。
- 数字转化为字符串 ,设某正整数为 N ,则字符串的空间复杂度为
,即转化的字符串长度为
,因此空间复杂度为
- 快速排序 ,平均空间复杂度为
# 线性
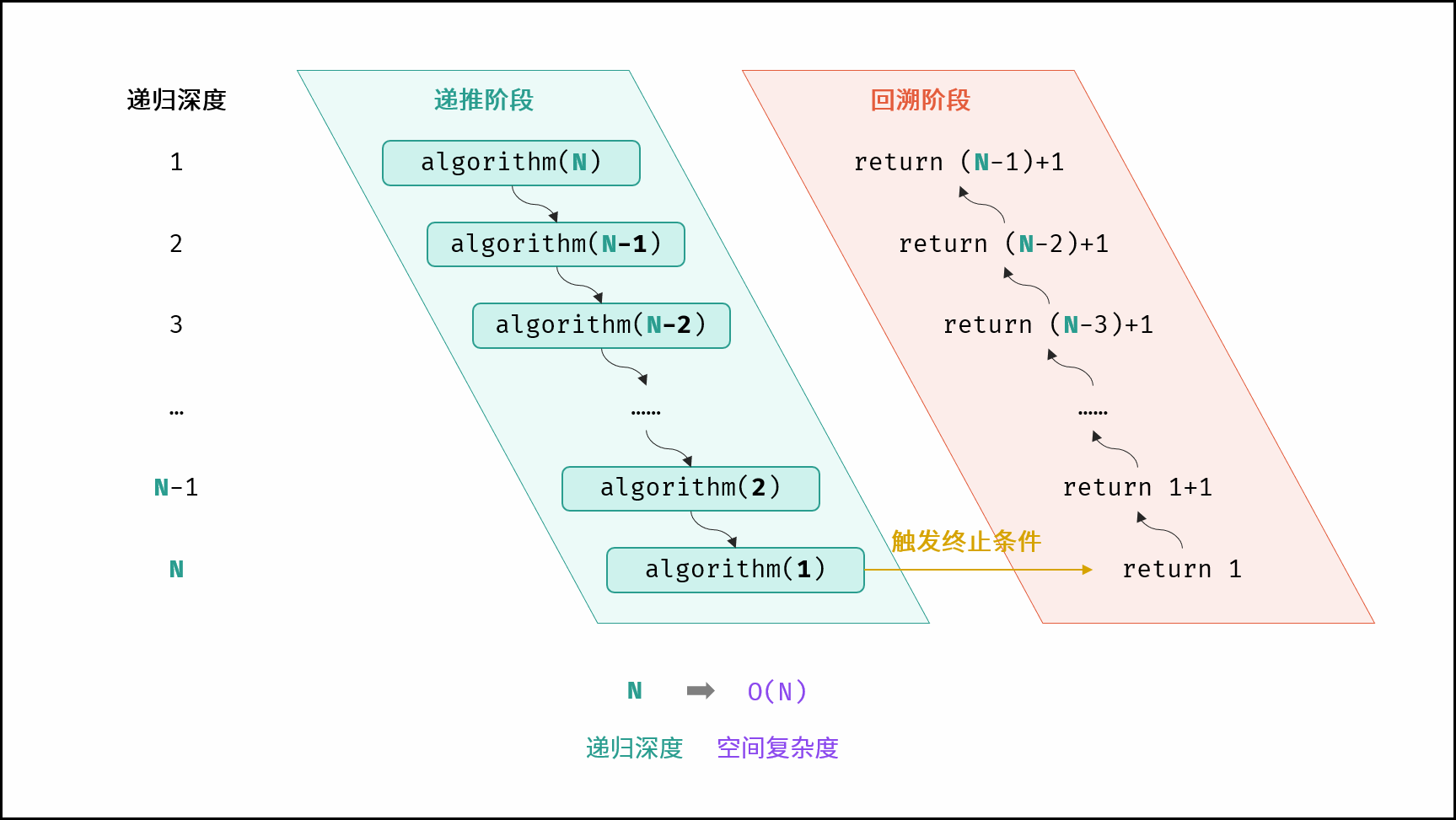
- 元素数量与 NN 呈线性关系的任意类型集合(常见于一维数组、链表、哈希表等),皆使用线性大小的空间。
- 如下图与代码所示,此递归调用期间,会同时存在 N 个未返回的
algorithm()函数,因此使用 O(N) 大小的栈帧空间。
int algorithm(int N) {
if (N <= 1) return 1;
return algorithm(N - 1) + 1;
}
2
3
4
# 平方
- 元素数量与 N 呈平方关系的任意类型集合(常见于矩阵),皆使用平方大小的空间。
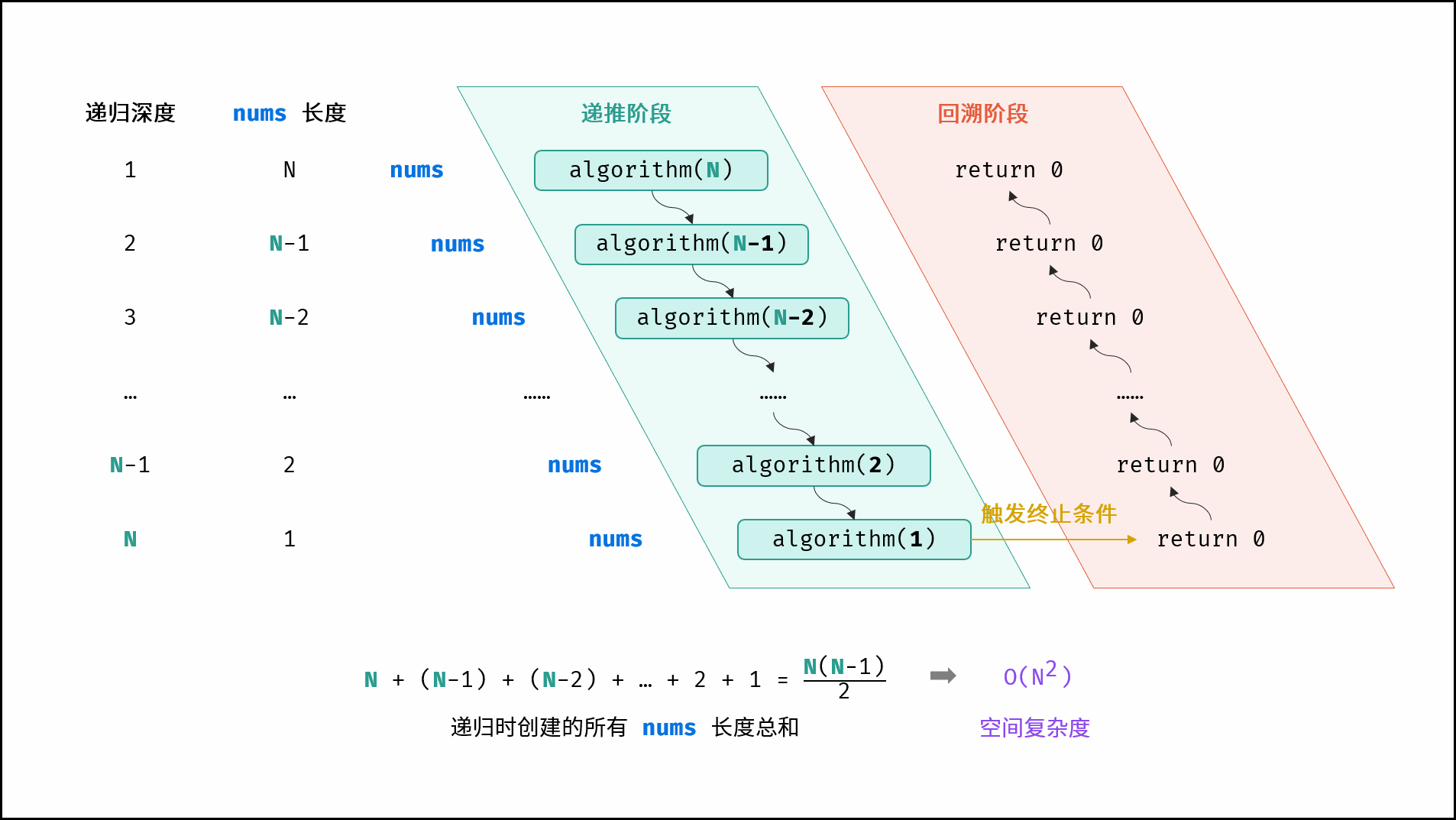
- 如下图与代码所示,递归调用时同时存在 N 个未返回的 algorithm() 函数,使用 O(N) 栈帧空间;每层递归函数中声明了数组,平均长度为
,使用 O(N) 空间;因此总体空间复杂度为
int algorithm(int N) {
if (N <= 0) return 0;
int[] nums = new int[N];
return algorithm(N - 1);
}
2
3
4
5
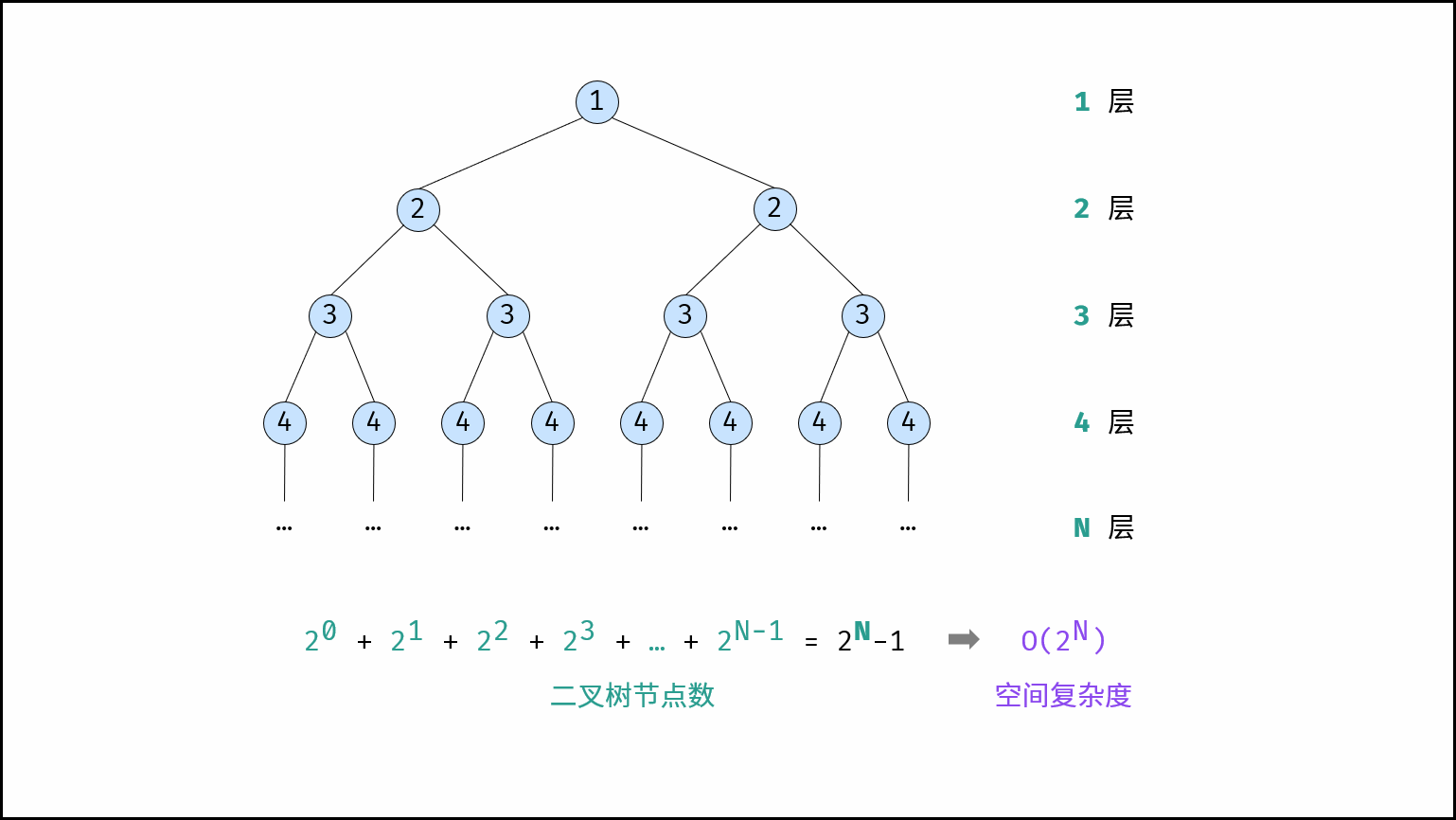
# 指数 
- 指数阶常见于二叉树、多叉树。例如,高度为 NN 的「满二叉树」的节点数量为
,占用
大小的空间。
# 时空权衡
对于算法的性能,需要从时间和空间的使用情况来综合评价。优良的算法应具备两个特性,即时间和空间复杂度皆较低。而实际上,对于某个算法问题,同时优化时间复杂度和空间复杂度是非常困难的。降低时间复杂度,往往是以提升空间复杂度为代价的,反之亦然。
由于当代计算机的内存充足,通常情况下,算法设计中一般会采取「空间换时间」的做法,即牺牲部分计算机存储空间,来提升算法的运行速度。
# 数组 (Array)

- 数组是将相同类型的元素存储于连续内存空间 (所以读取速度快)的数据结构,其长度不可变 (static)。
- 构建此数组需要在初始化时给定长度,并对数组每个索引元素赋值
// 初始化一个长度为 5 的数组 array
int[] array = new int[5];
// 元素赋值
array[0] = 2;
array[1] = 3;
array[2] = 1;
array[3] = 0;
array[4] = 2;
// 直接初始化 + 赋值
int[] array = {2, 3, 1, 0, 2};
System.out.println(Arrays.toString(array));
2
3
4
5
6
7
8
9
10
11
12
13
Simplest data structure
Static
- Great when you know how many items you have
- Can become dynamic
- ArrayList
Lookup by index: O(1)
Lookup by value: O(n)
- Have to iterate through all items
Insert to the end : O(n)
- Need to create a bigger array and reallocate all data to the new array
Remove an item
- Delete the last one: O(1)
Best Case - Delete the first one: O(n)
Worst Case- Need to move all data to front
- Delete the last one: O(1)
**「可变数组」**是经常使用的数据结构,其基于数组和扩容机制实现,相比普通数组更加灵活。常用操作有:访问元素、添加元素、删除元素。
// 初始化可变数组
ArrayList<Integer> list = new ArrayList<>();
// 向尾部添加元素
list.add(10);
list.add(20);
list.add(30);
list.remove(0); // index
list.contains(20);
list.indexOf(20);
list.lastIndexOf(20);
list.size();
list.toArray(); // convert to regular array object
System.out.println(list.indexOf(10)) //0, return index
System.out.println(list.indexOf(100)) // -1, because doesn't exist
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 链表 (Linked List)
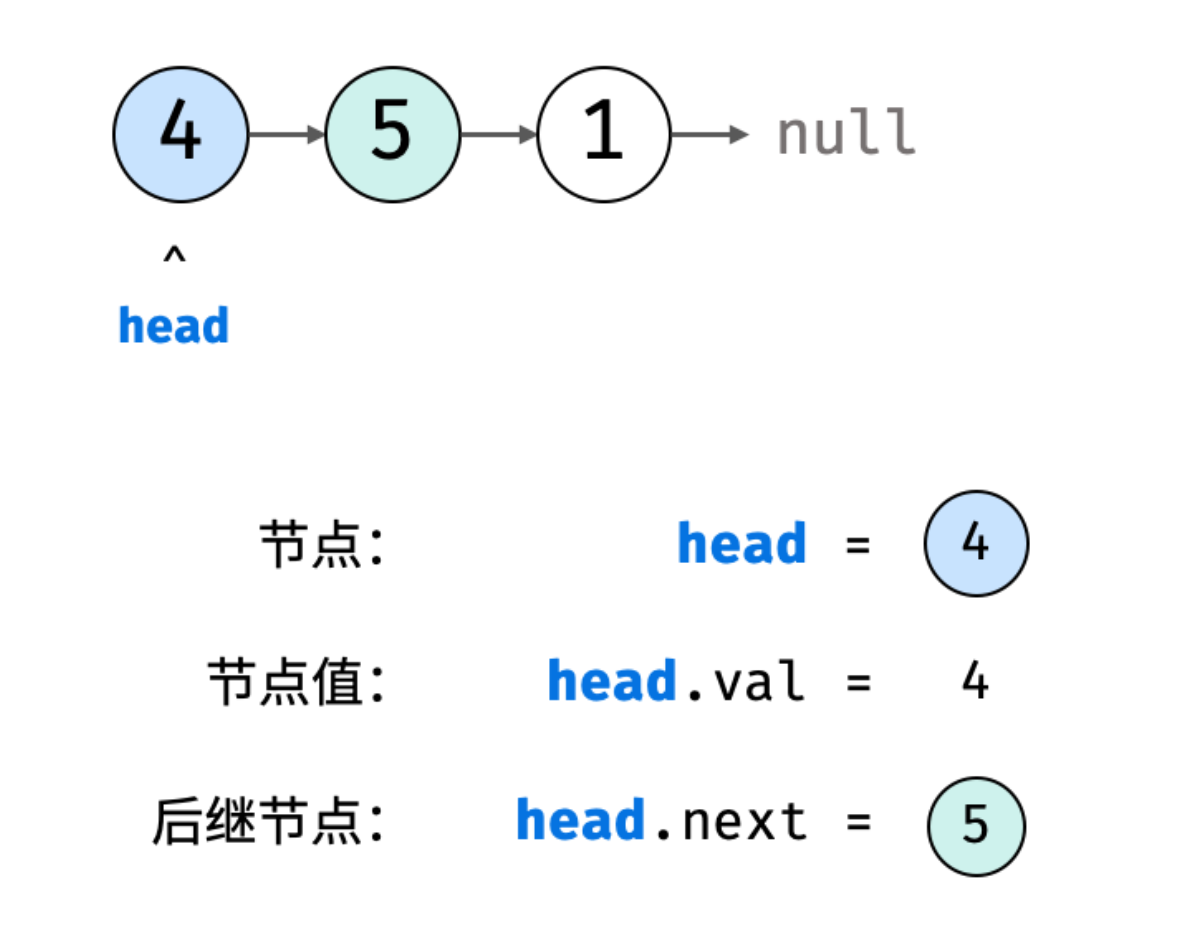
- 链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的
- 链表的节点对象具有两个成员变量:「值
val」(Value),「后继节点引用next」(Address) - 第一个 node 是 head,最后一个 node 是 tail
- 如下图所示,建立此链表需要实例化每个节点,并构建各节点的引用指向
class ListNode {
int val; // 节点值
ListNode next; // 后继节点引用
ListNode(int x) { val = x; }
}
// 实例化节点
ListNode n1 = new ListNode(4); // 节点 head
ListNode n2 = new ListNode(5);
ListNode n3 = new ListNode(1);
// 构建引用指向
n1.next = n2;
n2.next = n3;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- Lookup by value: O(n)
- Look up by index: O(n)
- Insert at the end: O(1)
- If there is reference to the tail node
- Insert at the beginning: O(1)
- There is always reference to the head node
- Insert in the middle: O(n)
- Find that node: O(n)
- Update the list: O(1)
# 栈(Stack)
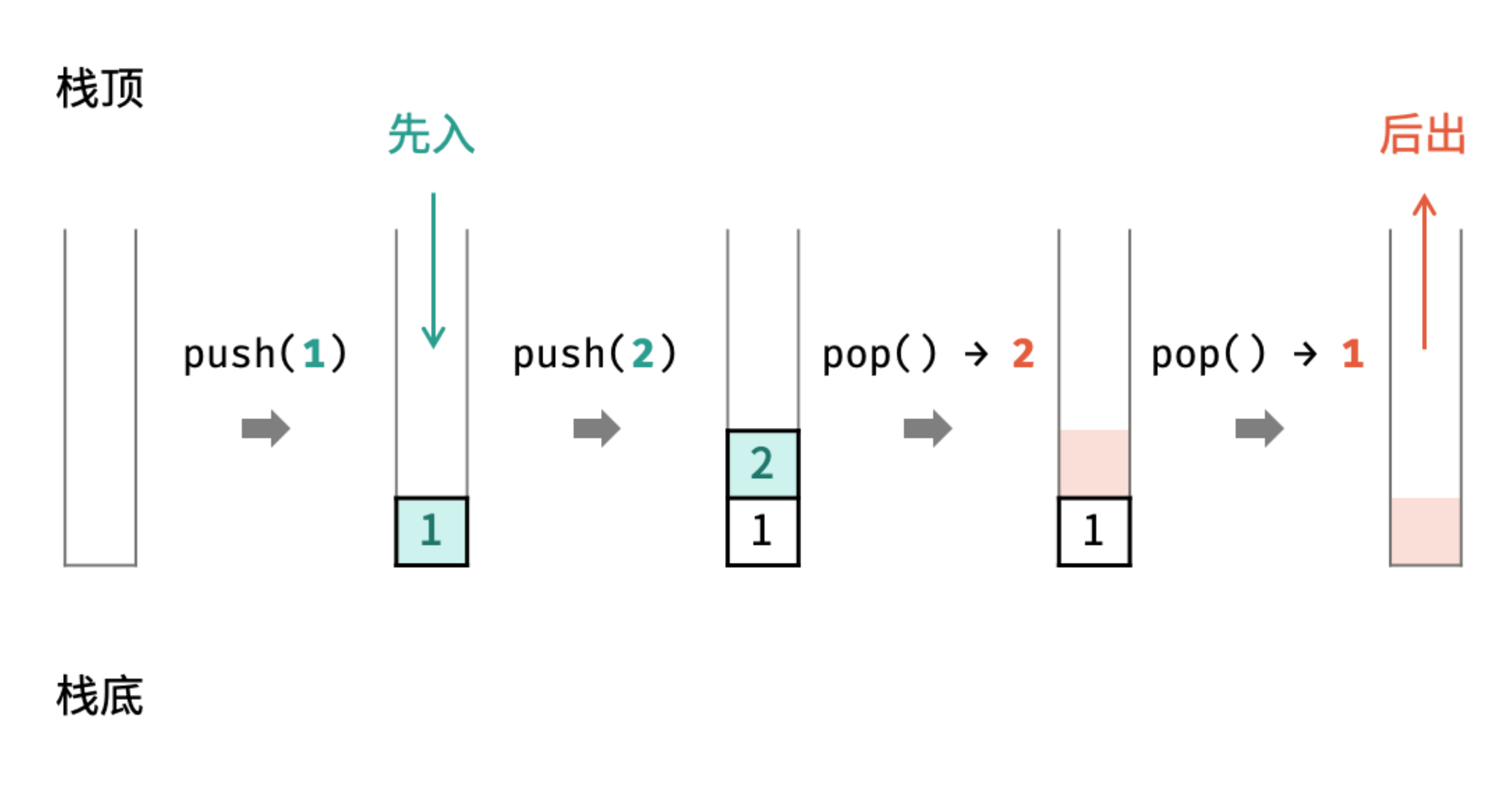
- 栈是一种具有 「先入后出」 特点的抽象数据结构,可使用数组或链表实现。
- 通过常用操作「入栈
push()」,「出栈pop()」,展示了栈的先入后出特性。
Stack<Integer> stack = new Stack<>();
stack.push(1); // 元素 1 入栈
stack.push(2); // 元素 2 入栈
stack.pop(); // 出栈 -> 元素 2
stack.pop(); // 出栈 -> 元素 1
2
3
4
5
6
- 注意:通常情况下,不推荐使用 Java 的
Vector以及其子类Stack,而一般将LinkedList作为栈来使用。
LinkedList<Integer> stack = new LinkedList<>();
stack.addLast(1); // 元素 1 入栈
stack.addLast(2); // 元素 2 入栈
stack.removeLast(); // 出栈 -> 元素 2
stack.removeLast(); // 出栈 -> 元素 1
2
3
4
5
6
# 队列 (Queue)
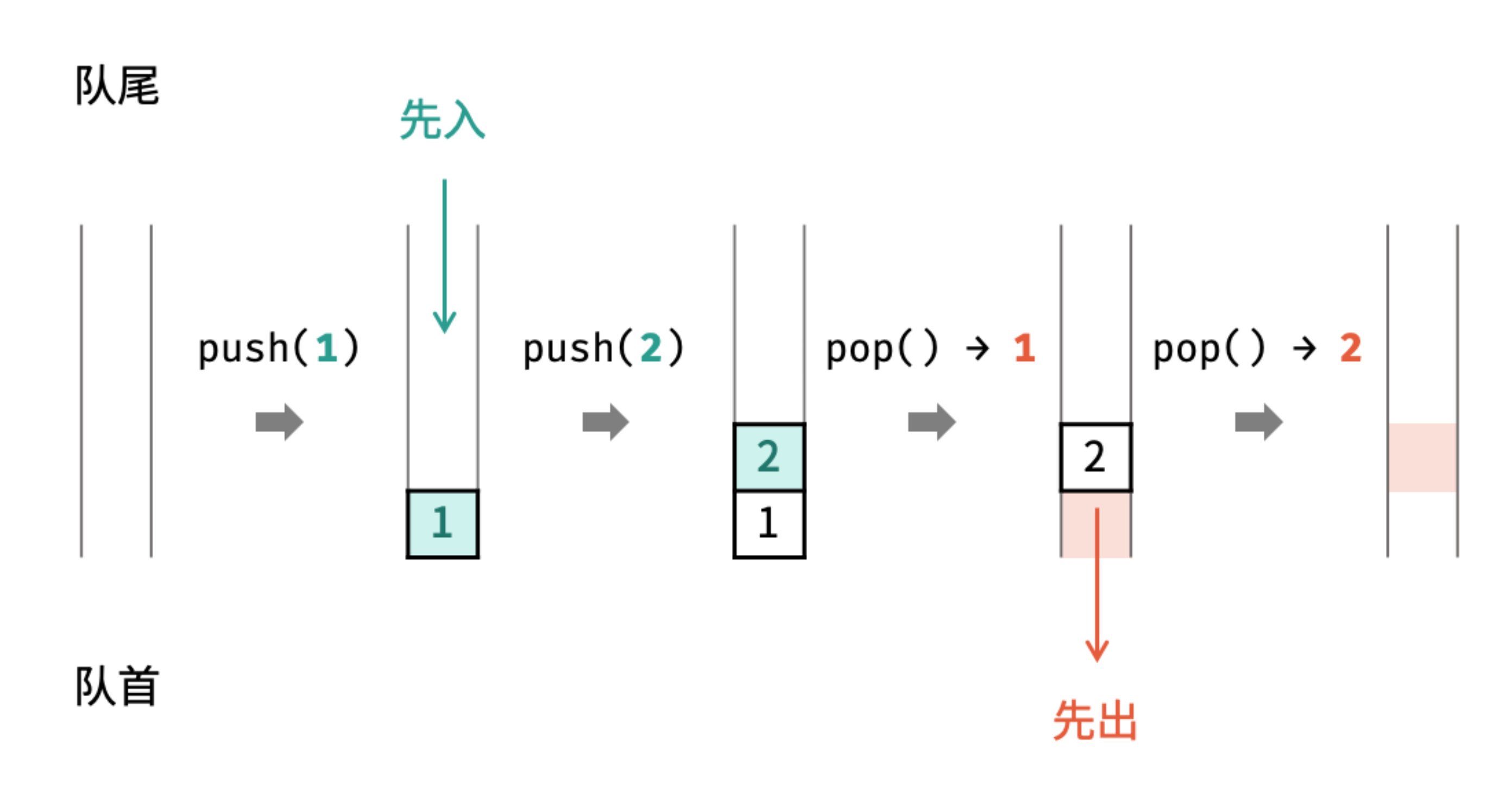
- 队列是一种具有 「先入先出」 特点的抽象数据结构,可使用链表实现。
- 通过常用操作「入队
offer()」,「出队poll()」,展示了队列的先入先出特性。
Queue<Integer> queue = new LinkedList<>();
queue.offer(1); // 元素 1 入队
queue.offer(2); // 元素 2 入队
queue.poll(); // 出队 -> 元素 1
queue.poll(); // 出队 -> 元素 2
2
3
4
5
6
# 树 (Tree)
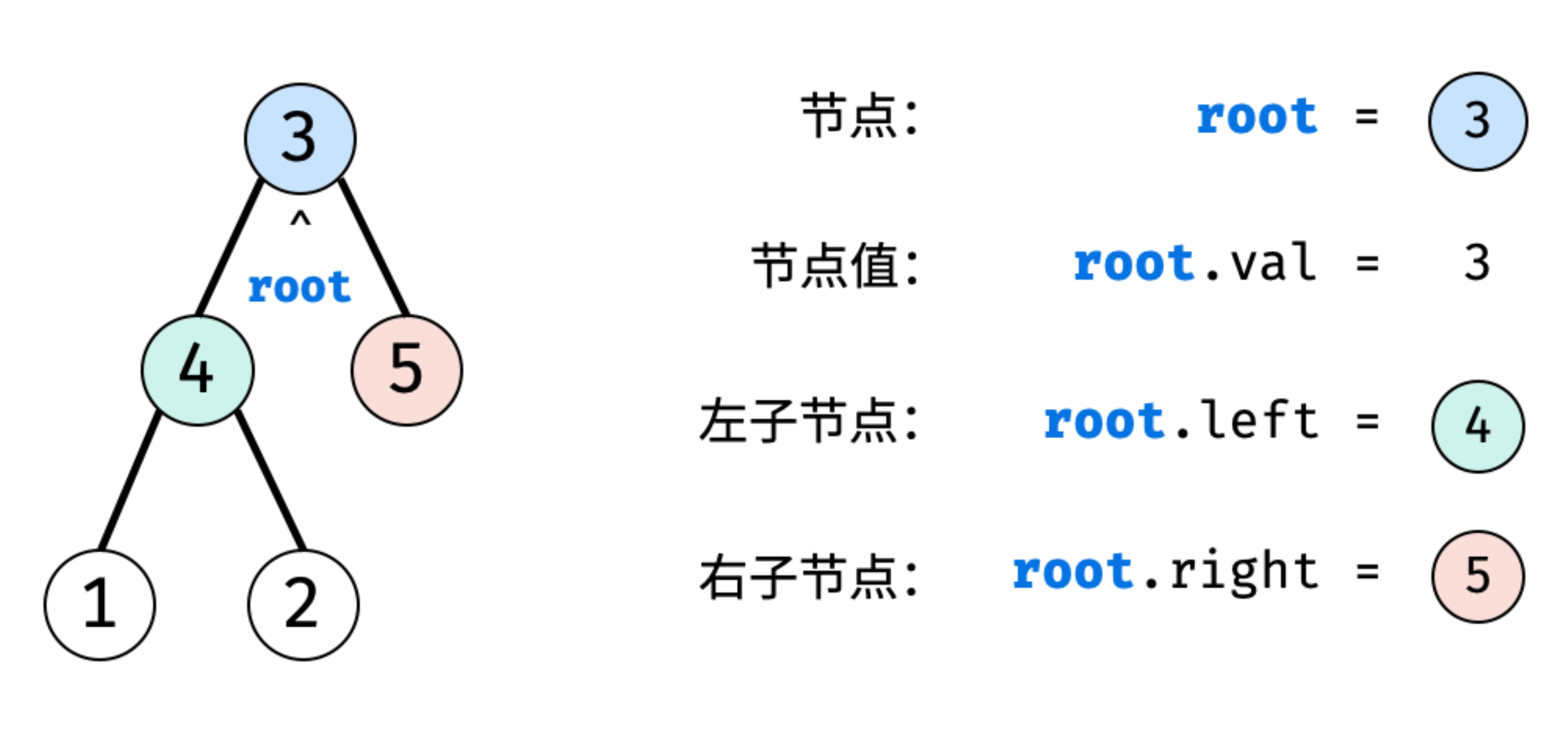
- 树是一种非线性数据结
- 根据子节点数量可分为 「二叉树」 和 「多叉树」
- 最顶层的节点称为「根节点 root」
- 以二叉树为例,每个节点包含三个成员变量:
- 「值 val」
- 「左子节点 left」
- 「右子节点 right」
- 建立此二叉树需要实例化每个节点,并构建各节点的引用指向
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点
TreeNode right; // 右子节点
TreeNode(int x) { val = x; }
}
// 初始化节点
TreeNode n1 = new TreeNode(3); // 根节点 root
TreeNode n2 = new TreeNode(4);
TreeNode n3 = new TreeNode(5);
TreeNode n4 = new TreeNode(1);
TreeNode n5 = new TreeNode(2);
// 构建引用指向
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 图 (Graph)
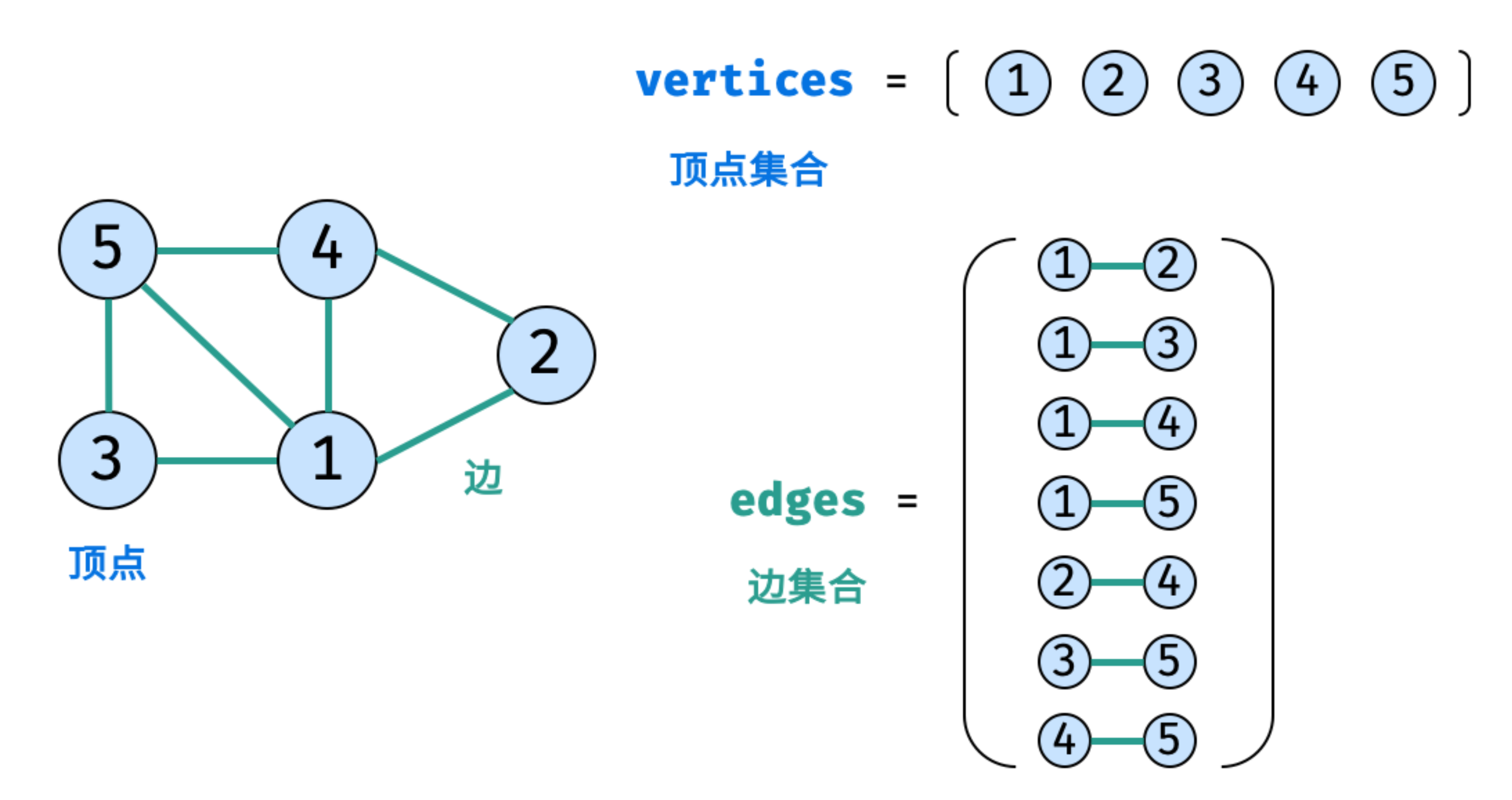
- 图是一种非线性数据结构,由「节点(顶点)vertex」和「边 edge」组成,每条边连接一对顶点
- 根据边的方向有无,图可分为「有向图」和「无向图」
表示图的方法通常有两种:
# 邻接矩阵
- 使用数组 vertices 存储顶点,邻接矩阵 edges 存储边
- Edges [i] [j]代表节点 i + 1 和 节点 j + 1 之间是否有边。
int[] vertices = {1, 2, 3, 4, 5};
int[][] edges = {{0, 1, 1, 1, 1},
{1, 0, 0, 1, 0},
{1, 0, 0, 0, 1},
{1, 1, 0, 0, 1},
{1, 0, 1, 1, 0}};
2
3
4
5
6
# 邻接表
- 使用数组 vertices 存储顶点,邻接表 edges 存储边
- edges 为一个二维容器,第一维 i 代表顶点索引,第二维 edges[i] 存储此顶点对应的边集合
- 例如 edges[0] = [1, 2, 3, 4] 代表 vertices[0] 的边集合为 [1, 2, 3, 4][1,2,3,4] 。
int[] vertices = {1, 2, 3, 4, 5};
ArrayList<ArrayList<Integer>> edges = new ArrayList<>();
ArrayList<Integer> edge_1 = new ArrayList<>(Arrays.asList(1, 2, 3, 4));
ArrayList<Integer> edge_2 = new ArrayList<>(Arrays.asList(0, 3));
ArrayList<Integer> edge_3 = new ArrayList<>(Arrays.asList(0, 4));
ArrayList<Integer> edge_4 = new ArrayList<>(Arrays.asList(0, 1, 4));
ArrayList<Integer> edge_5 = new ArrayList<>(Arrays.asList(0, 2, 3));
edges.add(edge_1);
edges.add(edge_2);
edges.add(edge_3);
edges.add(edge_4);
edges.add(edge_5);
2
3
4
5
6
7
8
9
10
11
12
13
14
# 邻接矩阵 VS 邻接表 :
- 邻接矩阵的大小只与节点数量有关,即
,其中 N 为节点数量。因此,当边数量明显少于节点数量时,使用邻接矩阵存储图会造成较大的内存浪费
- 因此,
- 邻接表 适合存储稀疏图(顶点较多、边较少);
- 邻接矩阵 适合存储稠密图(顶点较少、边较多)。
# 散列表 (Hash Table)
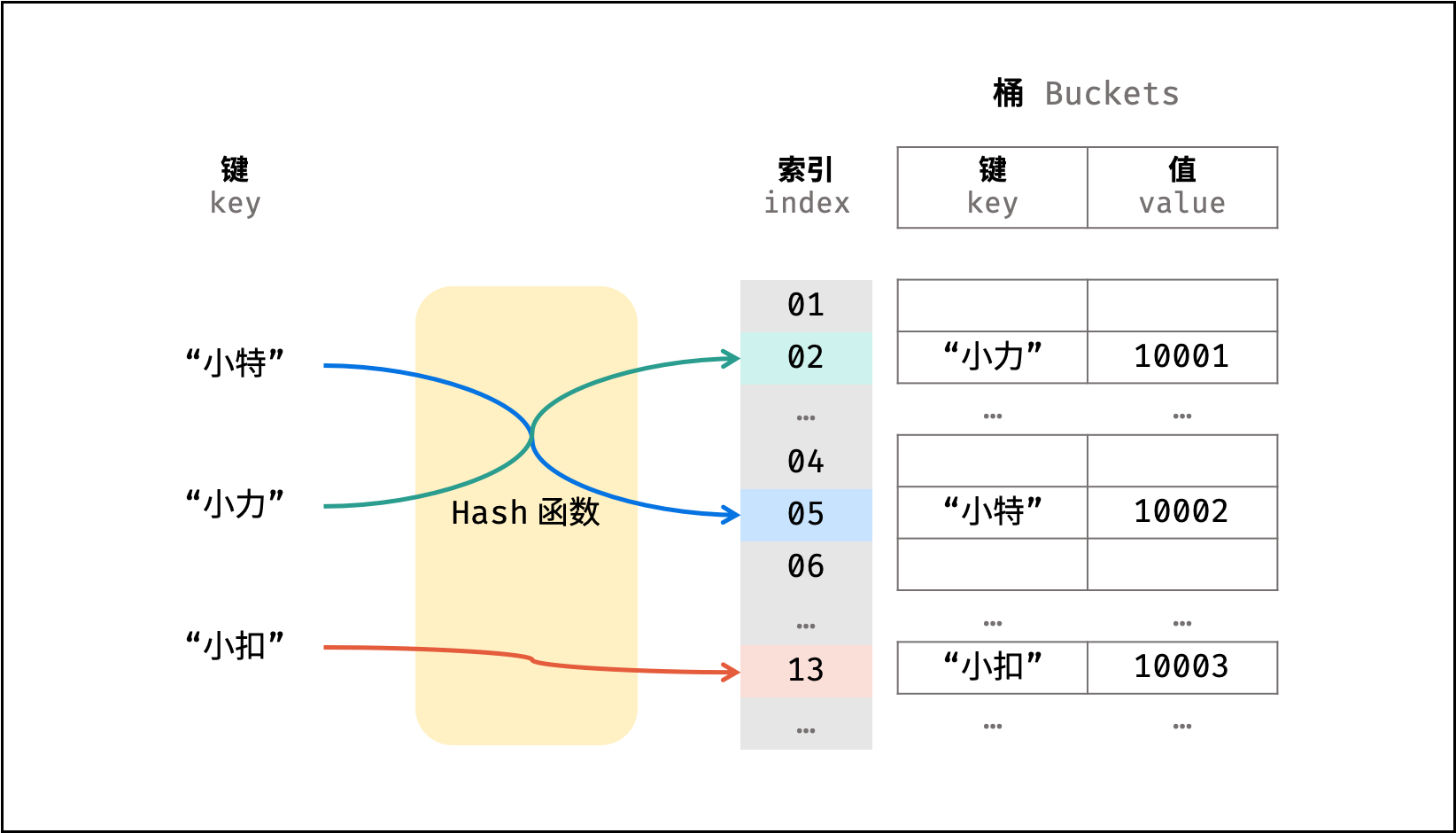
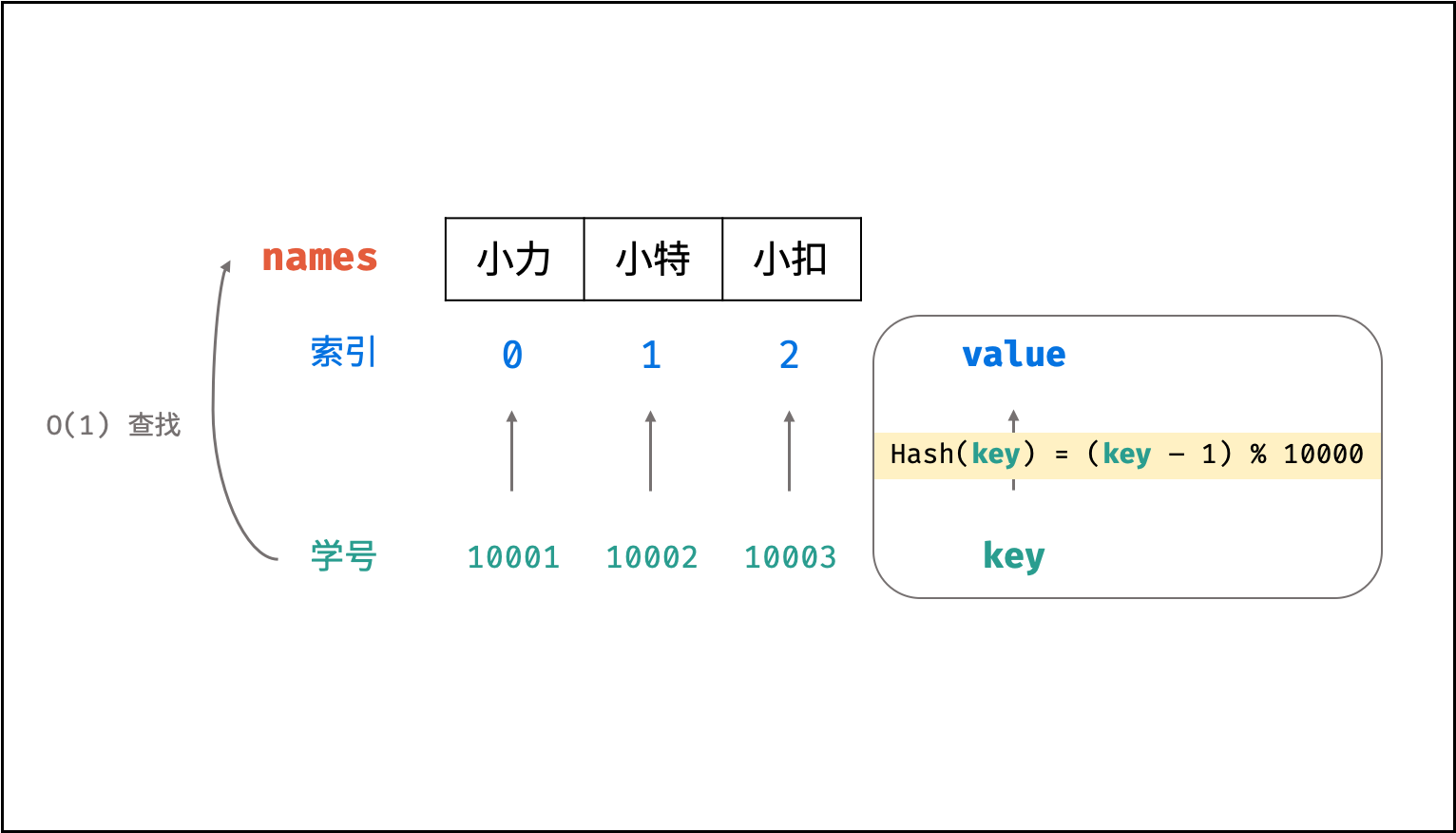
String[] names = { "小力", "小特", "小扣" };
// 一个简单的 Hash 函数( % 为取余符号 )
int hash(int id) {
int index = (id - 1) % 10000;
return index;
}
// 构建了以学号为 key 、姓名对应的数组索引为 value 的散列表。利用此 Hash 函数,则可在 O(1) 时间复杂度下通过学号查找到对应姓名:
names[hash(10001)] // 小力
names[hash(10002)] // 小特
names[hash(10003)] // 小扣
// 实际的 Hash 函数需保证低碰撞率、 高健壮性
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 堆 (Heap)
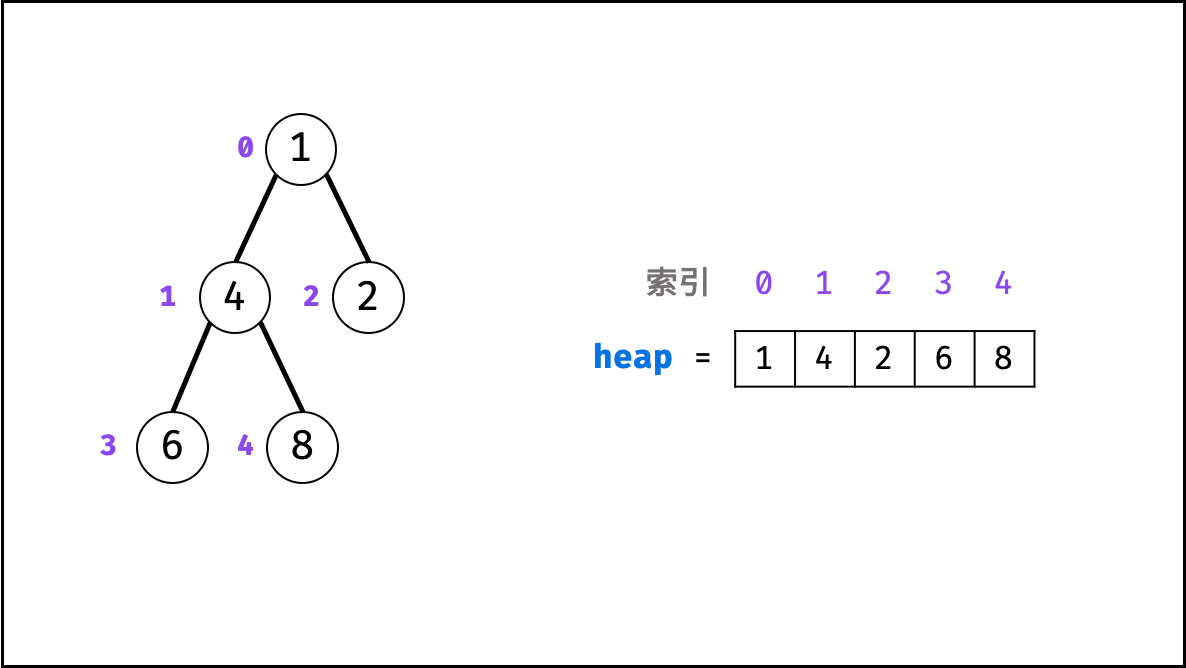
堆是一种基于「完全二叉树」的数据结构,可使用数组实现
以堆为原理的排序算法称为「堆排序」,基于堆实现的数据结构为「优先队列」(Priority Queue)
堆分为「大顶堆」和「小顶堆」,
- 大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
完全二叉树定义:
- 设二叉树深度为 k ,若二叉树除第 k 层外的其它各层(第 1 至 k-1 层)的节点达到最大个数,且处于第 k 层的节点都连续集中在最左边,则称此二叉树为完全二叉树。
- 如上图所示,为包含
1, 4, 2, 6, 8元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。
通过使用「优先队列」的「压入
push()」和「弹出pop()」操作,即可完成堆排序:
// 初始化小顶堆
Queue<Integer> heap = new PriorityQueue<>();
// 元素入堆
heap.add(1);
heap.add(4);
heap.add(2);
heap.add(6);
heap.add(8);
// 元素出堆(从小到大)
heap.poll(); // -> 1
heap.poll(); // -> 2
heap.poll(); // -> 4
heap.poll(); // -> 6
heap.poll(); // -> 8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16